
超越Logits:语言建模中的三元民主崛起
内容提要
现代语言模型在标记预测中存在缺陷,庞大的softmax层导致架构臃肿且易出错。引入三元编码(tribits)可以提升模型的表达能力和容错性,克服传统token化的局限,增强模型的鲁棒性和可解释性,标志着后softmax时代的到来。
关键要点
-
现代语言模型在标记预测中存在缺陷,庞大的softmax层导致架构臃肿且易出错。
-
引入三元编码(tribits)可以提升模型的表达能力和容错性,克服传统token化的局限。
-
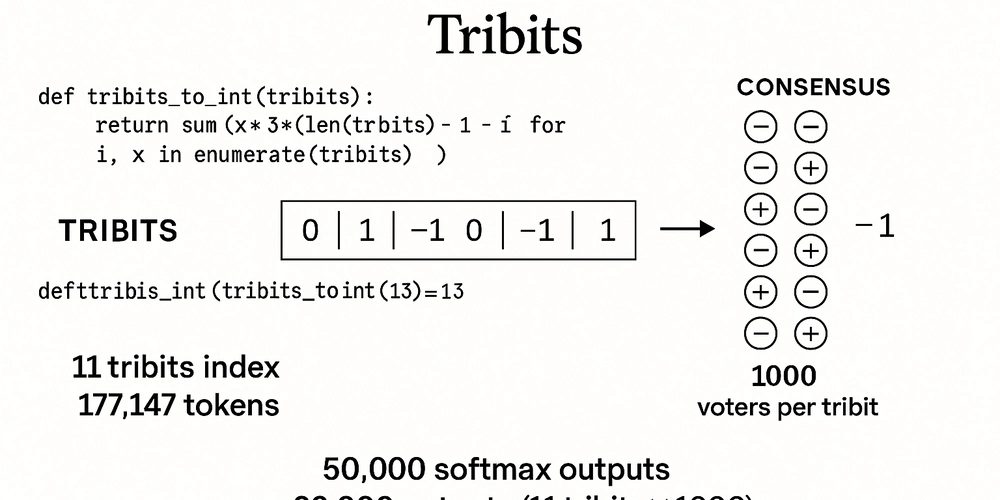
三元编码允许更大的表达能力和错误容忍度,模型可以通过冗余和分布式投票来恢复失败。
-
从二进制(base-2)切换到三元(base-3)显著增加了容量,每个额外的tribit携带更多信息。
-
使用tribits可以直接存储语言的完整性,而不需要粗糙的token化技巧。
-
每个tribit由多个神经元投票决定,形成小型民主决策,而不是依赖单一的softmax输出。
-
tribits的冗余容量使得模型能够编码多个正确输出,即使部分神经元投票受到干扰,仍能正确解析。
-
tribit模型重新定义了“预测一个token”的含义,提供了更小的输出头、更好的可解释性和更高的容错性。
-
在后softmax时代,模型的设计将更加高效、快速且对小的推理噪声几乎免疫。
延伸解读
三元编码的优势
三元编码(tribits)通过将每个token表示为多个神经元的投票结果,显著提升了模型的表达能力和容错性。这种方法不仅增加了信息容量,还允许模型在面对噪声时依然能够做出正确的预测,展示了其在语言建模中的潜力。
后softmax时代的意义
随着三元编码的引入,语言模型的设计将进入后softmax时代。这一转变意味着模型将更加高效,能够处理更复杂的语言结构,同时减少对庞大softmax层的依赖,提升了模型的可解释性和鲁棒性。
模型设计的未来
采用三元编码的模型设计不仅在参数数量上更为精简,还能通过冗余和分布式投票机制提高容错能力。这种新方法可能会改变未来语言模型的构建方式,使其在处理复杂语言任务时更加灵活和高效。
延伸问答
现代语言模型在标记预测中存在哪些缺陷?
现代语言模型的标记预测依赖庞大的softmax层,导致架构臃肿且易出错,且需要记忆超过50,000个离散类的映射。
什么是三元编码(tribits),它如何改善语言模型?
三元编码(tribits)通过将标记表示为多个神经元的投票结果,提升了模型的表达能力和容错性,克服了传统token化的局限。
三元编码相比于二进制编码有什么优势?
三元编码显著增加了容量,每个额外的tribit携带更多信息,允许模型编码更多的输出,提升了表达能力和错误容忍度。
如何通过三元编码实现模型的容错性?
三元编码的冗余容量允许模型编码多个正确输出,即使部分神经元投票受到干扰,仍能正确解析。
三元编码如何改变对“预测一个token”的理解?
三元编码重新定义了“预测一个token”的含义,通过小型民主决策而非单一的softmax输出,提供了更好的可解释性和容错性。
后softmax时代的语言模型设计有什么特点?
后softmax时代的语言模型设计将更加高效、快速且对小的推理噪声几乎免疫,采用更小的输出头和更好的可解释性。
