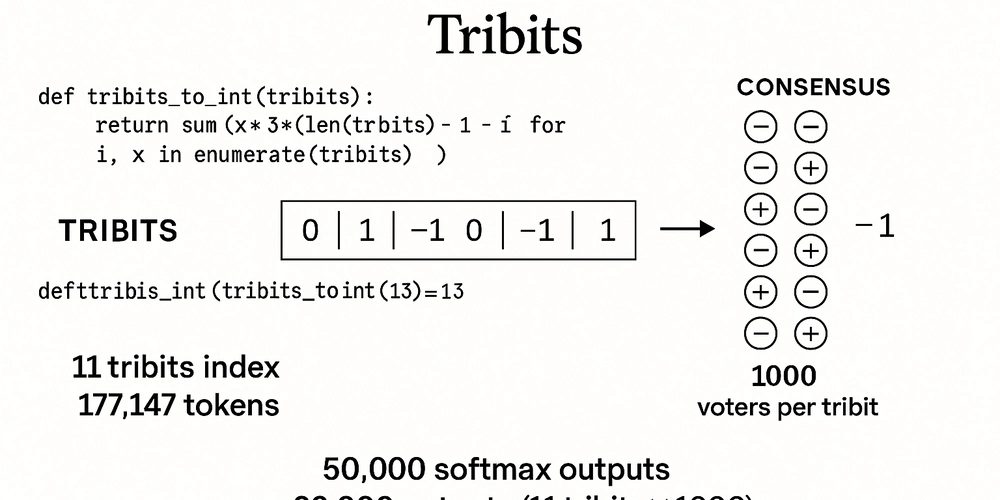
现代语言模型在标记预测中存在缺陷,庞大的softmax层导致架构臃肿且易出错。引入三元编码(tribits)可以提升模型的表达能力和容错性,克服传统token化的局限,增强模型的鲁棒性和可解释性,标志着后softmax时代的到来。
本研究提出了一种粗到细的标记预测方法,解决自回归图像生成中的量化误差问题。实验结果显示,Inception分数平均提升59分,且采样速度更快。
本研究提出了一个理论框架,探讨大型语言模型在下一个标记预测任务中的长度泛化问题,发现每个预测标记依赖于固定数量的前置标记,并提出了“预测位置耦合”方法以提升模型的泛化能力。
本文介绍了一种混合方法,通过上下文学习训练专家,结合示例子集和可训练的加权函数,预测专家的下一个标记,适用于黑箱大型语言模型。
通过27小时行走数据训练全尺寸仿人机器人,在旧金山自由行走。研究将仿人控制视为标记预测问题,通过传感器运动轨迹的自回归预测训练模型。结果表明,模型能在现实世界中泛化,并执行未见过的指令。研究为学习真实世界控制任务提供了前景广阔的道路。
完成下面两步后,将自动完成登录并继续当前操作。