

OpenAI如何利用Kubernetes和Apache Kafka进行生成式AI
💡
原文英文,约2800词,阅读约需10分钟。
📝
内容提要
OpenAI开发了一个流处理平台,利用PyFlink和Kubernetes,解决了Python优先、云资源限制和多主Kafka配置等问题,实现高可用性和故障转移,确保AI模型快速处理新数据,提高研发效率。
🎯
关键要点
- OpenAI开发了一个流处理平台,利用PyFlink和Kubernetes,解决了Python优先、云资源限制和多主Kafka配置等问题。
- 流处理平台能够实现高可用性和故障转移,确保AI模型快速处理新数据。
- 流处理使得数据几乎实时处理,避免了批处理带来的数据过时问题。
- OpenAI的工程团队设计了一个以PyFlink为中心的平台,满足可扩展性、可靠性和容错性。
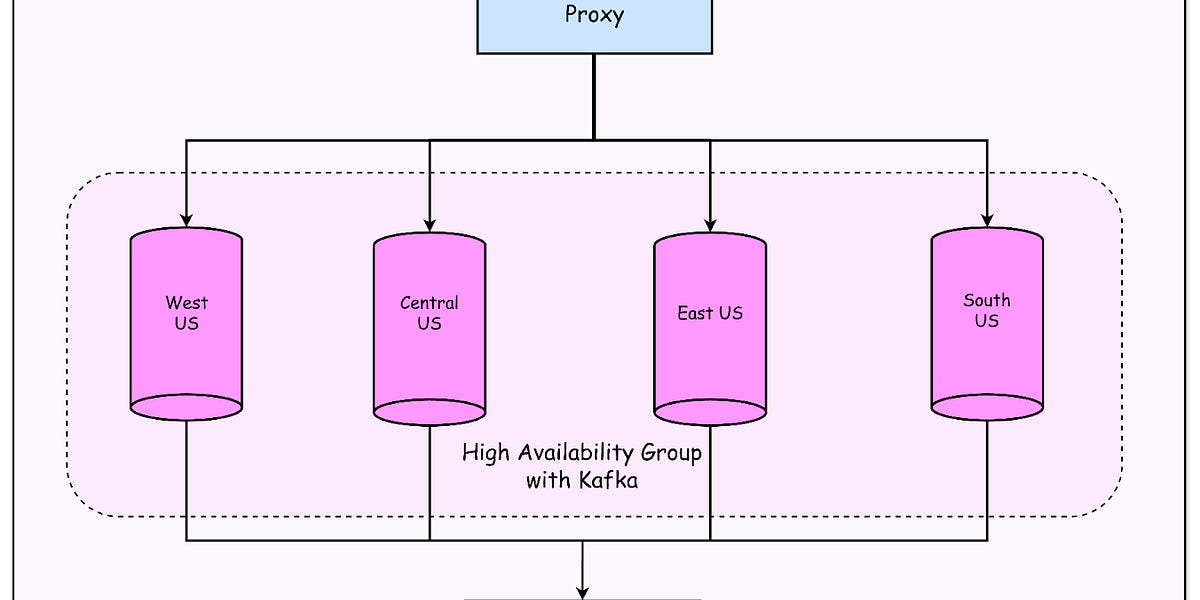
- 主要挑战包括Python在AI开发中的主导地位、云容量和可扩展性限制,以及多主Kafka配置的复杂性。
- 平台架构包括控制平面、Kubernetes设置、监控服务和状态管理,确保系统的可靠性和可用性。
- PyFlink提供了Python友好的流处理接口,支持DataStream API和Table/SQL API。
- Kafka连接器设计解决了多主Kafka环境下的可靠性问题,确保数据流的稳定性。
- 高可用性和故障转移机制确保在云环境中即使发生故障,流处理平台也能持续运行。
- OpenAI的流处理平台展示了如何将流处理与AI研究需求相结合,推动更快速的创新和模型改进。
➡️
