
OpenAI如何利用Kubernetes和Apache Kafka进行生成式AI
内容提要
OpenAI开发了一个流处理平台,利用PyFlink和Kubernetes,解决了Python优先、云资源限制和多主Kafka配置等问题,实现高可用性和故障转移,确保AI模型快速处理新数据,提高研发效率。
关键要点
-
OpenAI开发了一个流处理平台,利用PyFlink和Kubernetes,解决了Python优先、云资源限制和多主Kafka配置等问题。
-
流处理平台能够实现高可用性和故障转移,确保AI模型快速处理新数据。
-
流处理使得数据几乎实时处理,避免了批处理带来的数据过时问题。
-
OpenAI的工程团队设计了一个以PyFlink为中心的平台,满足可扩展性、可靠性和容错性。
-
主要挑战包括Python在AI开发中的主导地位、云容量和可扩展性限制,以及多主Kafka配置的复杂性。
-
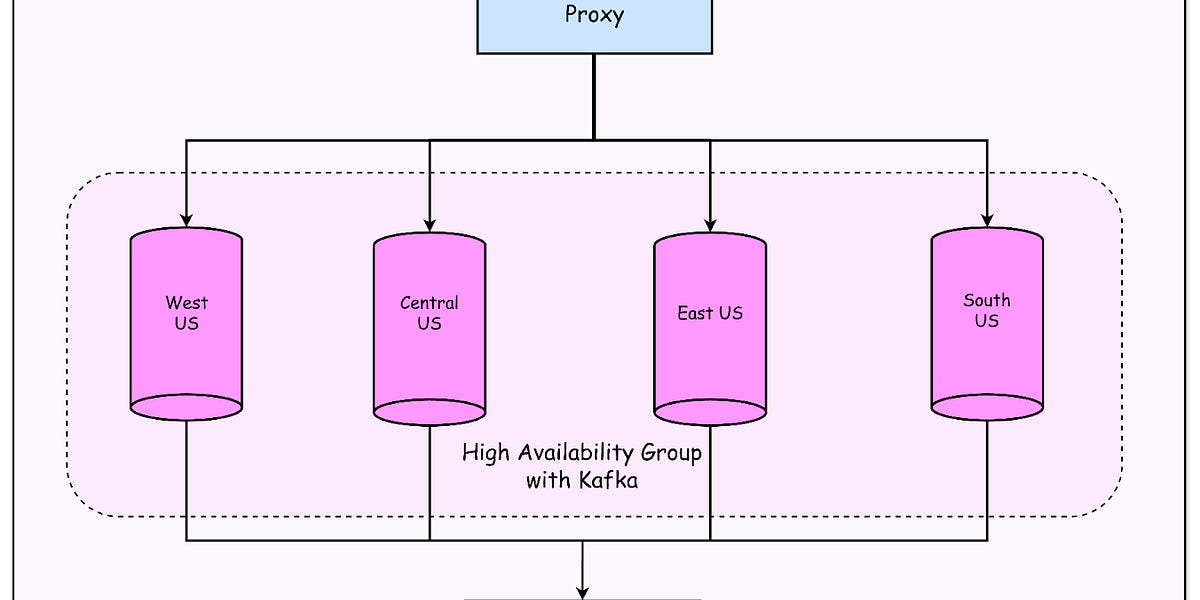
平台架构包括控制平面、Kubernetes设置、监控服务和状态管理,确保系统的可靠性和可用性。
-
PyFlink提供了Python友好的流处理接口,支持DataStream API和Table/SQL API。
-
Kafka连接器设计解决了多主Kafka环境下的可靠性问题,确保数据流的稳定性。
-
高可用性和故障转移机制确保在云环境中即使发生故障,流处理平台也能持续运行。
-
OpenAI的流处理平台展示了如何将流处理与AI研究需求相结合,推动更快速的创新和模型改进。
延伸解读
流处理的优势
OpenAI的流处理平台通过实时处理数据,避免了批处理带来的数据过时问题。这种几乎实时的数据处理方式使得AI模型能够快速获取新数据,从而提升模型的准确性和响应速度。对于需要快速迭代和实验的AI研究,流处理显得尤为重要。
高可用性的重要性
在云环境中,系统故障是常见的挑战。OpenAI通过设计高可用性和故障转移机制,确保流处理平台在发生故障时仍能持续运行。这种设计不仅提高了系统的可靠性,也为AI研究提供了稳定的基础,避免了因系统中断而导致的研究延误。
PyFlink的局限性
尽管PyFlink为Python开发者提供了友好的流处理接口,但仍存在一些局限性。例如,某些性能关键的功能需要用Java编写并封装,且目前不支持异步I/O和流连接等高级用例。这些限制可能影响开发者的使用体验,需关注未来的改进方向。
延伸问答
OpenAI的流处理平台是如何解决Python优先的问题的?
OpenAI通过采用和扩展PyFlink,提供Python友好的流处理接口,确保数据管道对机器学习从业者来说自然易用。
OpenAI的流处理平台如何确保高可用性和故障转移?
平台通过控制平面管理作业,支持多集群故障转移,确保即使在云环境中发生故障,流处理也能持续运行。
流处理与批处理相比有什么优势?
流处理几乎实时处理数据,避免了批处理导致的数据过时问题,从而提供更新的训练数据和更快的实验反馈。
OpenAI在设计流处理平台时面临了哪些主要挑战?
主要挑战包括Python在AI开发中的主导地位、云容量和可扩展性限制,以及多主Kafka配置的复杂性。
PyFlink在OpenAI流处理平台中扮演什么角色?
PyFlink是OpenAI流处理平台的核心,提供Python接口,使开发者能够使用熟悉的工具编写数据管道。
OpenAI如何处理Kafka的多主配置问题?
OpenAI设计了自定义连接器,允许作业同时从多个主Kafka集群读取数据,确保在集群不可用时不会导致整个管道失败。
