
pyspark streaming简介 和 消费 kafka示例
内容提要
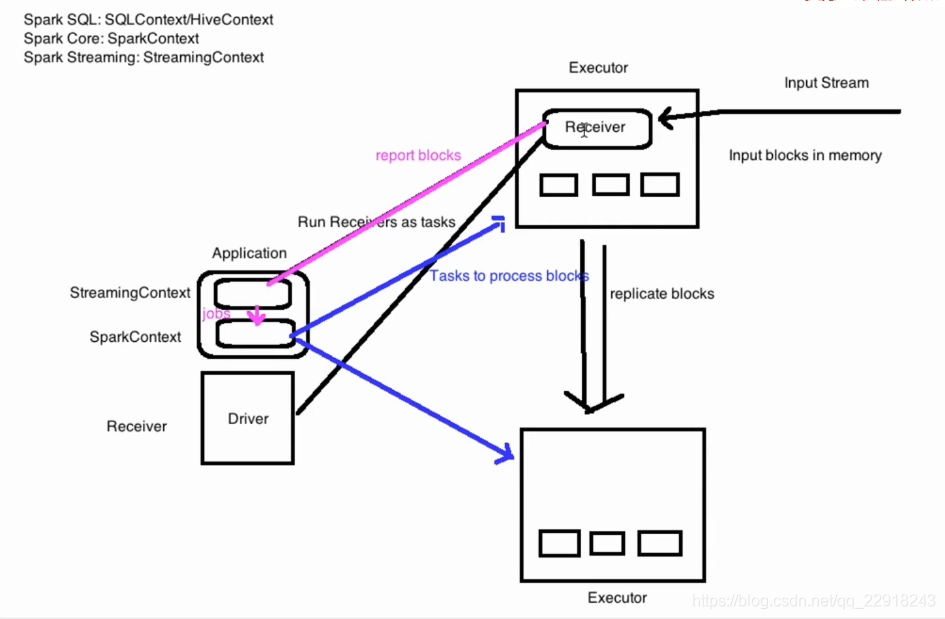
本文介绍了Spark Streaming的基础和高级数据源,包括通过socket和Kafka进行数据流处理的示例代码。基础数据源通过socket连接,展示了数据的读取与处理;高级数据源则整合Kafka,提供两种使用模式。
关键要点
-
本文介绍了Spark Streaming的基础和高级数据源。
-
基础数据源可以通过streamingContext API实现,包括文件系统和socket连接。
-
使用socket连接的示例代码展示了如何读取和处理数据。
-
高级数据源整合了Kafka,提供两种使用模式。
-
receiver模式的Kafka流处理示例代码展示了如何创建Kafka流。
-
可以使用createStream和createDirectStream两种方式连接Kafka。
-
运行程序需要下载相应的jar包,提供了下载地址。
延伸解读
Spark Streaming的应用场景
Spark Streaming适用于实时数据处理场景,如社交媒体分析、金融交易监控等。通过基础数据源和高级数据源的结合,用户可以灵活选择数据输入方式,满足不同的业务需求。
Kafka与Spark Streaming的整合
Kafka作为流处理的高级数据源,提供了高吞吐量和低延迟的特性。使用receiver模式和createDirectStream方式,用户可以根据需求选择合适的流处理模式,提升数据处理效率。
注意事项与风险
在使用Spark Streaming时,确保下载相应的jar包以避免运行错误。此外,配置Kafka连接时需注意broker地址的正确性,以确保数据流的稳定性和可靠性。
延伸问答
什么是Spark Streaming的基础数据源?
Spark Streaming的基础数据源可以通过streamingContext API实现,包括文件系统和socket连接。
如何通过socket连接进行数据流处理?
可以使用socketTextStream方法读取socket中的数据进行流处理,示例代码展示了如何实现。
Kafka在Spark Streaming中有哪些使用模式?
Kafka在Spark Streaming中提供两种使用模式:receiver模式和direct模式。
如何创建Kafka流?
可以使用KafkaUtils.createStream或KafkaUtils.createDirectStream方法来创建Kafka流。
运行Spark Streaming程序需要注意什么?
运行程序需要下载相应的jar包,并确保正确配置。
Spark Streaming如何处理文件系统数据?
Spark Streaming可以通过textFileStream方法处理文件系统数据,但需要确保文件路径正确。
