
如何使用 LlamaIndex 构建一个 RAG 检索系统
内容提要
本文介绍了如何使用 LlamaIndex 构建 RAG 检索系统,包括安装 VSCode 和 Python 环境,接入大语言模型 Ollama,创建知识库并向量化数据,最后实现检索功能。用户可以通过配置相关模块查询知识库并获取结果。
关键要点
-
LlamaIndex 是一个基于大语言模型的开源框架,用于构建 RAG 检索系统。
-
安装 VSCode 和 Python 环境,创建虚拟环境以支持 LlamaIndex 的运行。
-
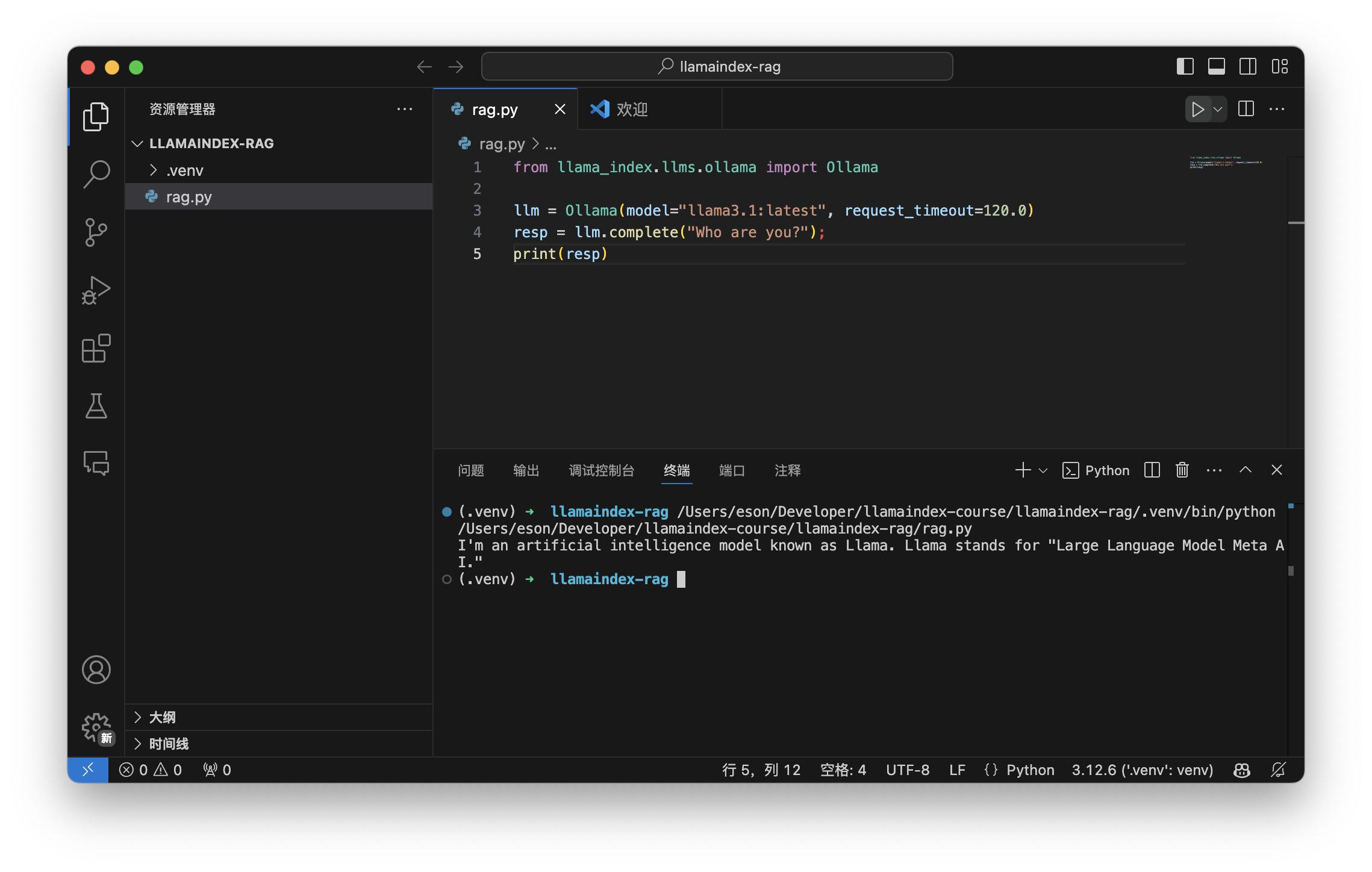
接入大语言模型 Ollama,安装并运行 llama 3.1 模型。
-
创建知识库,准备知识库示例文件,并支持多种文件格式。
-
安装必要的模块以构建知识库,使用 HuggingFace 的 embeddings 模型进行数据向量化。
-
将向量化的知识库保存到磁盘,以便后续检索。
-
实现检索功能,通过配置查询引擎从知识库中获取结果。
延伸解读
LlamaIndex 的优势与应用场景
LlamaIndex 是一个开源框架,利用大语言模型构建 RAG 检索系统,适合需要快速检索和处理大量信息的场景。它的灵活性使得用户可以根据需求定制知识库,适用于教育、研究和企业知识管理等领域。
环境配置的重要性
在使用 LlamaIndex 之前,正确配置 VSCode 和 Python 环境至关重要。创建虚拟环境可以避免依赖冲突,确保项目的可移植性和稳定性。用户应仔细遵循安装步骤,以减少后续开发中的问题。
数据向量化的关键步骤
数据向量化是构建 RAG 检索系统的核心步骤,使用 HuggingFace 的 embeddings 模型可以提高检索的准确性。用户在选择模型时应考虑数据类型和应用场景,以确保最佳效果。
延伸问答
LlamaIndex 是什么?
LlamaIndex 是一个基于大语言模型的开源框架,用于构建 RAG 检索系统。
如何安装 VSCode 和 Python 环境以使用 LlamaIndex?
首先下载并安装 VSCode,然后在 VSCode 中创建一个虚拟环境以支持 Python 运行。
如何接入大语言模型 Ollama?
通过在 VSCode 中打开终端,输入命令安装 Ollama,并运行 llama 3.1 模型。
如何创建和向量化知识库?
在 knowledge 目录下准备示例文件,安装必要模块后,使用 HuggingFace 的 embeddings 模型进行数据向量化。
如何实现检索功能?
在 rag.py 文件中配置查询引擎,通过 StorageContext 加载向量化的知识库并进行查询。
LlamaIndex 支持哪些文件格式?
LlamaIndex 支持多种文件格式,包括 .txt、.docx 和 .pdf 等。
