
💡
原文中文,约5500字,阅读约需14分钟。
📝
内容提要
Meta公司推出了一种紧凑型视觉编码器EUPE,能够同时处理多种视觉任务。它采用“先扩大规模,再缩小规模”的方法,将多个专家模型的知识整合到一个代理模型中,并提炼出高效的学生模型,从而解决边缘设备计算资源不足的问题。
🎯
关键要点
- Meta公司推出紧凑型视觉编码器EUPE,能够同时处理多种视觉任务。
- EUPE采用'先扩大规模,再缩小规模'的方法,将多个专家模型的知识整合到一个代理模型中。
- 视觉编码器将原始图像像素转换为紧凑表示形式,供下游任务使用。
- 传统的视觉编码器在精简后会失去功能,且专用模型在超出其能力范围时表现不佳。
- 以往的聚合式方法在高效骨干网络构建上未能奏效,主要是因为容量不足。
- EUPE的流程分为三个阶段:多教师模型提炼为代理模型、固定分辨率蒸馏到高效学生模型、多分辨率微调。
- 训练数据使用DINOv3数据集LVD-1689M,数据质量高于MetaCLIP。
- 教师模型的选择对性能有显著影响,增加教师数量并不总能改善结果。
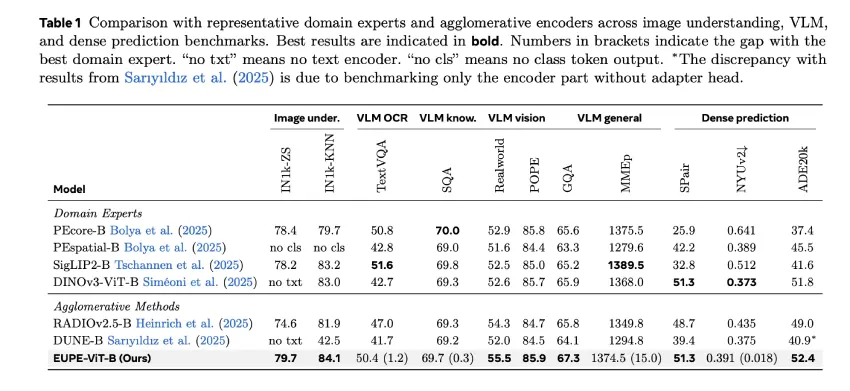
- EUPE在多个基准测试中表现优异,尤其在图像理解、密集预测和视觉语言建模方面。
- EUPE系列涵盖多种架构,所有模型参数量均低于1亿,适合边缘设备部署。
- 数据质量比数据数量更重要,较小的数据集在某些情况下能优于更大的数据集。
❓
延伸问答
EUPE视觉编码器的主要特点是什么?
EUPE是一款参数量低于1亿的紧凑型视觉编码器,能够同时处理多种视觉任务,适合边缘设备部署。
EUPE是如何解决边缘设备计算资源不足的问题的?
EUPE采用'先扩大规模,再缩小规模'的方法,将多个专家模型的知识整合到一个代理模型中,从而提炼出高效的学生模型。
EUPE在训练过程中使用了哪些数据集?
EUPE的训练数据使用了DINOv3数据集LVD-1689M,该数据集的质量高于MetaCLIP。
EUPE的训练流程分为几个阶段?
EUPE的训练流程分为三个阶段:多教师模型提炼为代理模型、固定分辨率蒸馏到高效学生模型、多分辨率微调。
EUPE在视觉语言建模方面的表现如何?
EUPE在视觉语言建模任务中表现优异,尤其在RealworldQA和GQA基准测试中得分高于其他模型。
为什么数据质量比数据数量更重要?
消融实验表明,基于LVD-1689M数据集训练的模型在几乎所有基准测试中优于基于MetaCLIP数据集训练的模型,尽管后者的图像数量更多。
➡️
