

💡
原文中文,约3000字,阅读约需8分钟。
📝
内容提要
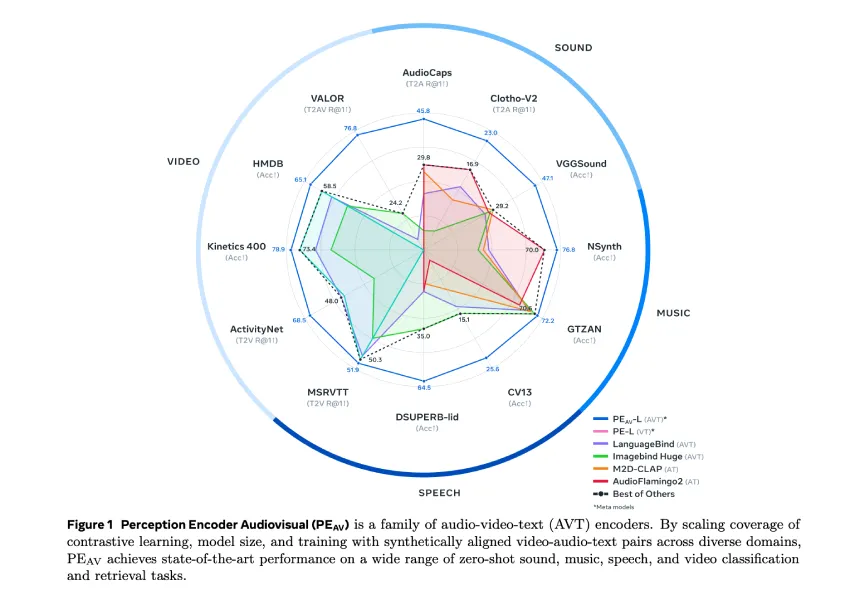
Meta推出了感知编码器视听模型(PE-AV),该模型通过对1亿个带字幕的音视频对进行训练,实现音频、视频和文本的对齐表示。PE-AV在多个基准测试中表现优异,支持跨模态检索和理解,并结合两阶段数据引擎生成合成字幕,提高了多模态监督的效率。
🎯
关键要点
- Meta推出了感知编码器视听模型(PE-AV),用于音频和视频的联合理解。
- PE-AV通过对1亿个带字幕的音视频对进行训练,实现音频、视频和文本的对齐表示。
- 该模型在多个基准测试中表现优异,支持跨模态检索和理解。
- PE-AV架构包括帧编码器、视频编码器、音频编码器、音视频融合编码器及文本编码器。
- 音频路径使用DAC VAE编解码器,将原始波形转换为离散音频令牌。
- 两阶段数据引擎生成高质量的合成字幕,第一阶段使用弱音频字幕模型,第二阶段与感知语言模型配对优化字幕。
- PE-AV在多个音频和视频基准测试中取得了最先进的性能,提升了检索和分类的准确率。
- PE A-Frame是用于声音事件定位的音频文本嵌入模型,能够精确定位音频中的事件。
- PE-AV和PE A-Frame是Meta感知模型堆栈的一部分,结合了视觉和语言模型用于多模态生成和推理。
- PE-AV通过对比学习在广泛的音频和视频基准测试中树立了新的技术水平。
➡️
