

💡
原文中文,约1800字,阅读约需5分钟。
📝
内容提要
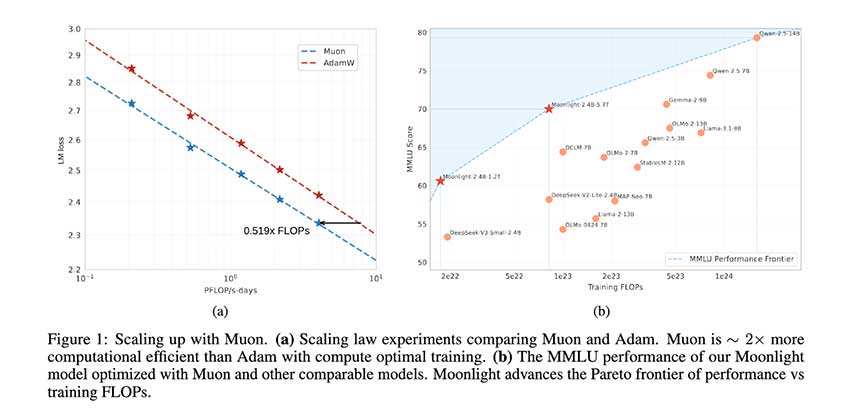
Muon优化器通过权重衰减和一致的RMS更新,提高了大规模语言模型的稳定性和效率,降低了计算成本。Moonlight模型表现优异,超越同类,支持多语言处理,推动高效训练方法的探索。
🎯
关键要点
- 优化大规模语言模型需要先进的训练技术,以降低计算成本并保持高性能。
- 现有优化器如AdamW需要细致的超参数调整和大量计算资源,效率低下。
- Muon优化器通过权重衰减和一致的RMS更新,提高了训练稳定性和效率。
- Moonlight模型使用5.7万亿个token进行训练,表现优异,超越同类模型。
- Moonlight在多个基准测试中表现出色,尤其在多语言处理任务中取得优异成绩。
- Muon的创新解决了训练大型模型的可扩展性挑战,降低了训练成本。
- Muon和Moonlight的开源促进了对大规模模型高效训练方法的探索。
➡️
