

Uber如何通过集成缓存每秒处理超过1.5亿次读取
💡
原文英文,约2000词,阅读约需8分钟。
📝
内容提要
Uber的CacheFront系统通过缓存技术提高数据读取效率,解决数据一致性问题,实现99.9%的缓存命中率,工程团队因此减少了70%以上的事件处理和调试时间。
🎯
关键要点
- Uber的CacheFront系统通过缓存技术提高数据读取效率,解决数据一致性问题。
- CacheFront实现了99.9%的缓存命中率,显著减少了事件处理和调试时间。
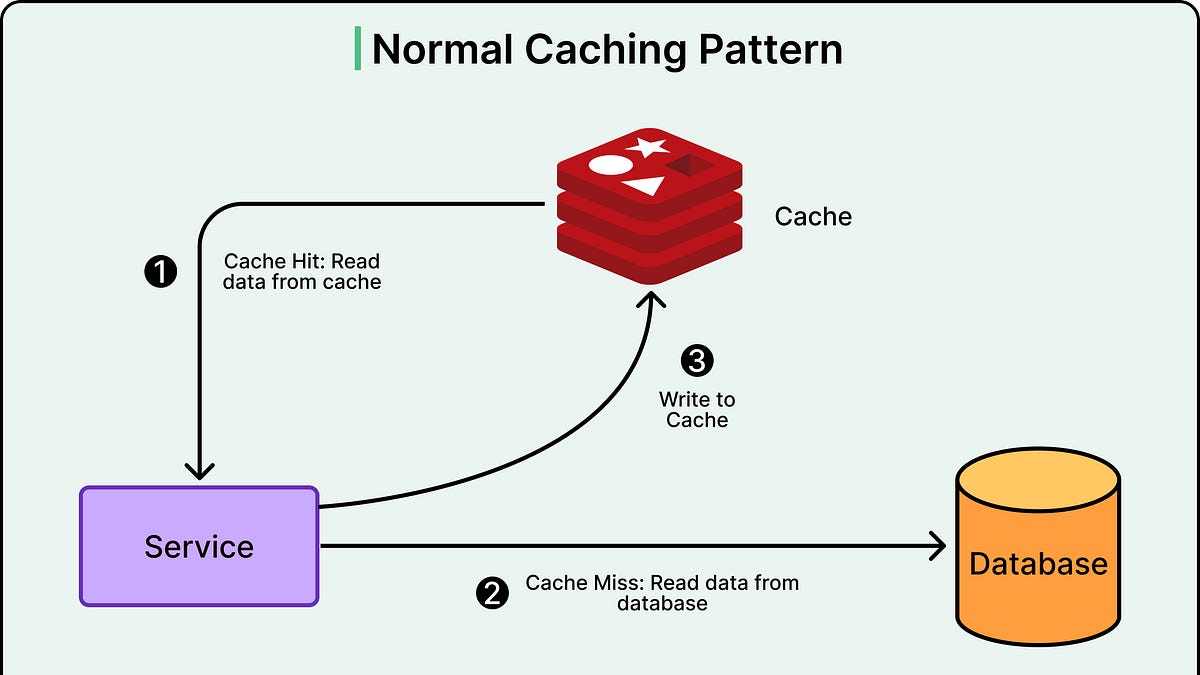
- Uber的存储系统Docstore由查询引擎、存储引擎和缓存逻辑组成。
- 缓存技术通过存储频繁访问的数据来减少数据库负载和延迟。
- 写操作引入了复杂性,尤其是条件更新时,缓存失效的管理变得困难。
- Uber最初使用Flux系统进行异步缓存失效管理,但存在一致性问题。
- 通过将删除操作转换为软删除和使用单调时间戳,Uber实现了同步缓存失效。
- CacheFront现在运行三种机制来保持缓存一致性:TTL过期、Flux异步失效和新的写路径失效。
- Cache Inspector工具用于验证缓存一致性,结果显示几乎没有过期值。
- CacheFront系统在高峰时段每秒处理超过1.5亿次请求,且一致性保证得到了提升。
➡️
