
BAAI推出OmniGen2:多模态人工智能的统一扩散和变压器模型
内容提要
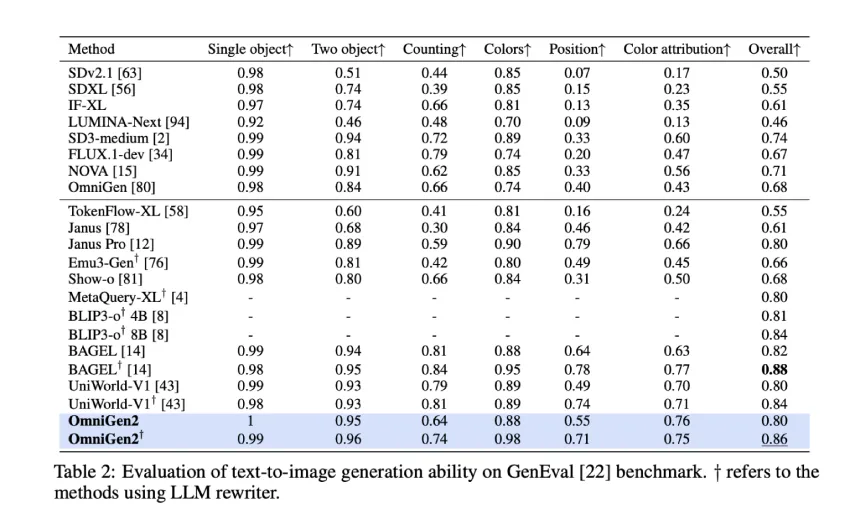
北京智源人工智能研究院推出了新一代开源多模态生成模型OmniGen2,具备文本转图像生成和图像编辑功能。该模型通过解耦文本与图像生成、采用反射训练机制,并引入OmniContext基准评估上下文一致性,表现优异,为图文生成研究奠定基础。
关键要点
-
北京智源人工智能研究院推出新一代开源多模态生成模型OmniGen2。
-
OmniGen2在文本转图像生成、图像编辑和主题驱动生成功能上进行了统一。
-
模型通过解耦文本与图像生成,采用反射训练机制,提升了生成质量。
-
引入OmniContext基准评估上下文一致性,OmniGen2在开源模型中表现优异。
-
反射机制通过反馈循环分析生成输出,提高了指令执行的准确性和视觉连贯性。
-
OmniGen2基于1.4亿个T2I样本和1000万张专有图像进行训练,数据集经过精心挑选。
-
在多个领域取得优异成果,包括文本到图像生成和图像编辑。
-
未来可能集中于强化学习,以实现反射细化和扩展模型的鲁棒性。
延伸解读
OmniGen2的创新机制
OmniGen2通过解耦文本与图像生成,采用反射训练机制,显著提升了生成质量。这种创新使得模型在处理复杂任务时,能够更好地理解和生成符合上下文的内容,尤其在图像编辑和主题驱动生成方面表现突出。
OmniContext基准的重要性
引入OmniContext基准测试为评估模型的上下文一致性提供了新的标准。通过对比不同任务类型的表现,研究人员能够更准确地识别模型的优缺点,从而推动多模态生成技术的进一步发展。
反射机制的应用前景
OmniGen2的反射机制通过反馈循环分析生成输出,提升了指令执行的准确性。这一机制不仅有助于提高模型的生成质量,还可能为未来的多模态生成研究提供新的思路,尤其是在自我校正和细微调整方面。
延伸问答
OmniGen2的主要功能是什么?
OmniGen2主要功能包括文本转图像生成、图像编辑和主题驱动生成功能。
OmniGen2是如何提高生成质量的?
OmniGen2通过解耦文本与图像生成、采用反射训练机制来提高生成质量。
OmniContext基准测试的目的是什么?
OmniContext基准测试用于评估模型的上下文一致性,涵盖角色、对象和场景类别。
OmniGen2的反射机制有什么特点?
OmniGen2的反射机制通过反馈循环分析生成输出,显著提高了指令执行的准确性和视觉连贯性。
OmniGen2的训练数据来源是什么?
OmniGen2基于1.4亿个T2I样本和1000万张专有图像进行训练,数据集经过精心挑选。
未来OmniGen2可能会有哪些改进方向?
未来OmniGen2可能集中于强化学习,以实现反射细化和扩展模型的鲁棒性。
