
Meta AI 发布 Apollo:用于视频理解的全新 Video-LMM 大型多模态模型系列
内容提要
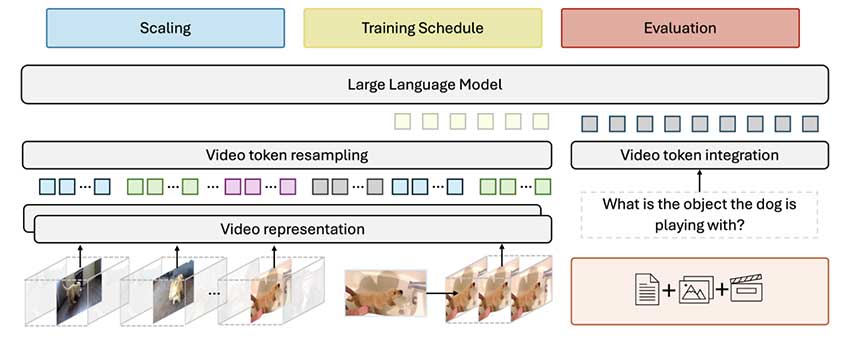
Meta AI与斯坦福大学联合开发的Apollo视频多模态模型,旨在提升视频理解能力。Apollo通过优化设计和双视觉编码器,支持处理最长一小时的视频,性能超越多种大型模型,为视频问答和内容分析提供有效解决方案。
关键要点
-
Meta AI与斯坦福大学联合开发Apollo视频多模态模型,旨在提升视频理解能力。
-
Apollo支持处理最长一小时的视频,性能超越多种大型模型。
-
现有视频模型面临计算资源需求高和难以捕捉运动时间模式的问题。
-
Apollo通过优化设计和双视觉编码器解决视频理解的挑战。
-
Apollo模型有三种大小,适应不同计算约束和需求。
-
每秒帧数采样技术提高了视频时间一致性。
-
双视觉编码器结合空间理解和时间推理,提供更准确的视频表示。
-
Apollo采用三阶段训练流程,确保稳定有效的学习。
-
Apollo支持基于视频内容的多轮对话,适用于聊天系统和内容分析。
-
Apollo在多个基准测试中表现优异,超越了许多大型模型。
-
Apollo为视频理解提供了实用而强大的解决方案,推动了视频LMM的发展。
延伸解读
视频理解的技术挑战
视频理解涉及复杂的空间和时间维度,现有模型往往难以有效捕捉运动模式。Apollo通过双视觉编码器和每秒帧数采样技术,解决了这些技术挑战,提升了视频分析的准确性和效率。
模型的灵活性与适应性
Apollo系列提供三种不同大小的模型,适应不同的计算资源和需求。这种灵活性使得开发者可以根据实际情况选择合适的模型,降低了高性能视频理解的门槛。
基准测试的重要性
Apollo在多个基准测试中表现优异,超越了许多大型模型。这表明,经过充分研究的设计和训练策略对模型性能的提升至关重要,为未来的研究提供了有价值的参考。
延伸问答
Apollo模型的主要目标是什么?
Apollo模型旨在提升视频理解能力,解决现有视频模型的计算资源需求高和难以捕捉运动时间模式的问题。
Apollo模型支持处理多长时间的视频?
Apollo模型支持处理最长一小时的视频。
Apollo模型采用了什么样的编码器设计?
Apollo模型采用双视觉编码器,结合了用于空间理解的SigLIP和用于时间推理的InternVideo2。
Apollo模型的训练流程是怎样的?
Apollo采用三阶段训练流程,首先微调视频编码器,然后与文本和图像数据集集成。
Apollo模型在基准测试中的表现如何?
Apollo模型在多个基准测试中表现优异,通常超越了许多大型模型。
Apollo模型适用于哪些应用场景?
Apollo模型适用于基于视频的多轮对话、聊天系统和内容分析等应用。
