
Grab如何构建视觉大语言模型以扫描图像
💡
原文英文,约2400词,阅读约需9分钟。
📝
内容提要
Grab团队开发了一种轻量级视觉大语言模型(Vision LLM),旨在提升东南亚语言的文档处理能力。通过合成数据和自动标注框架Documint,优化了OCR和关键信息提取的准确性,最终模型在准确性和延迟方面表现优异,展示了专用模型在文档处理中的潜力。
🎯
关键要点
-
Grab团队开发了一种轻量级视觉大语言模型(Vision LLM),旨在提升东南亚语言的文档处理能力。
-
传统的光学字符识别(OCR)系统在处理多样化文档模板时面临重大挑战。
-
Grab选择了Qwen2-VL 2B作为基础多模态LLM,因其适合的模型大小和对东南亚语言的良好支持。
-
Grab开发了两种生成训练数据的方法:合成OCR数据集和Documint自动标注框架。
-
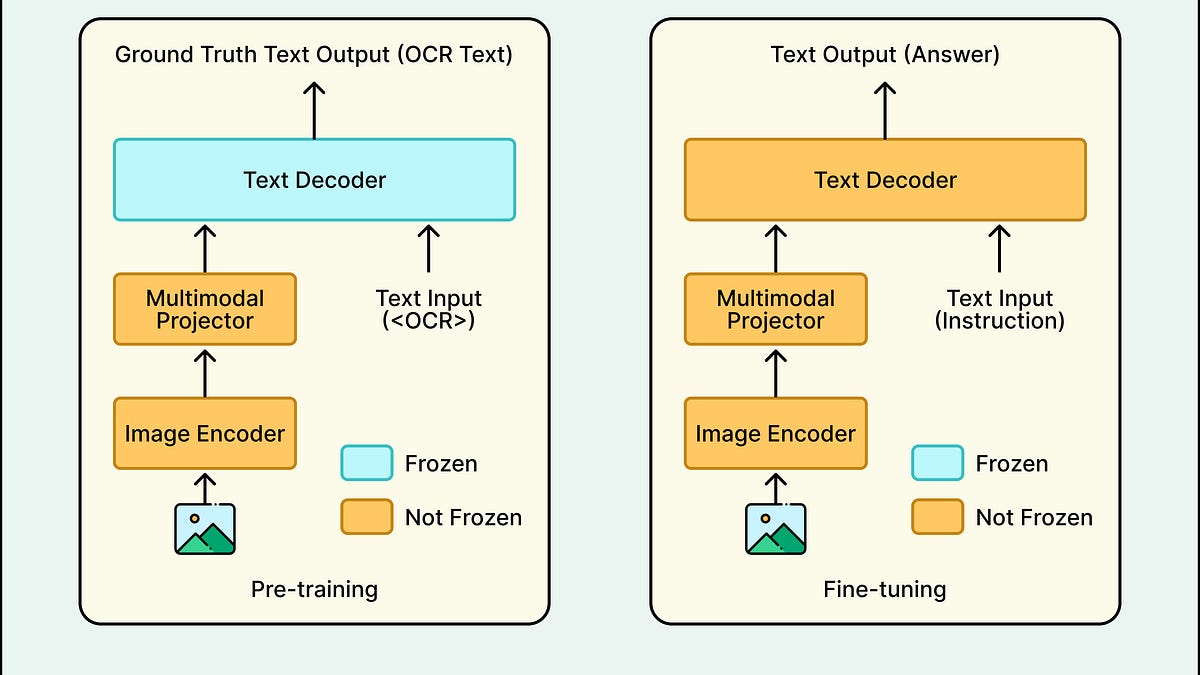
模型开发分为三个阶段:LoRA微调、全参数微调和从头构建1B模型。
-
最终的1B模型在准确性和延迟方面表现优异,处理速度比2B模型快48%。
-
全参数微调在处理非拉丁文档时优于LoRA,轻量级模型也能取得接近最先进的结果。
-
数据质量和模型架构设计对最终模型的成功至关重要,动态分辨率支持显著提升OCR能力。
-
Grab的项目展示了专用视觉LLM可以有效替代传统OCR管道,提升文档处理的速度和准确性。
➡️
