

宣布无服务器和标准集群上分布式机器学习的公测
💡
原文英文,约300词,阅读约需1分钟。
📝
内容提要
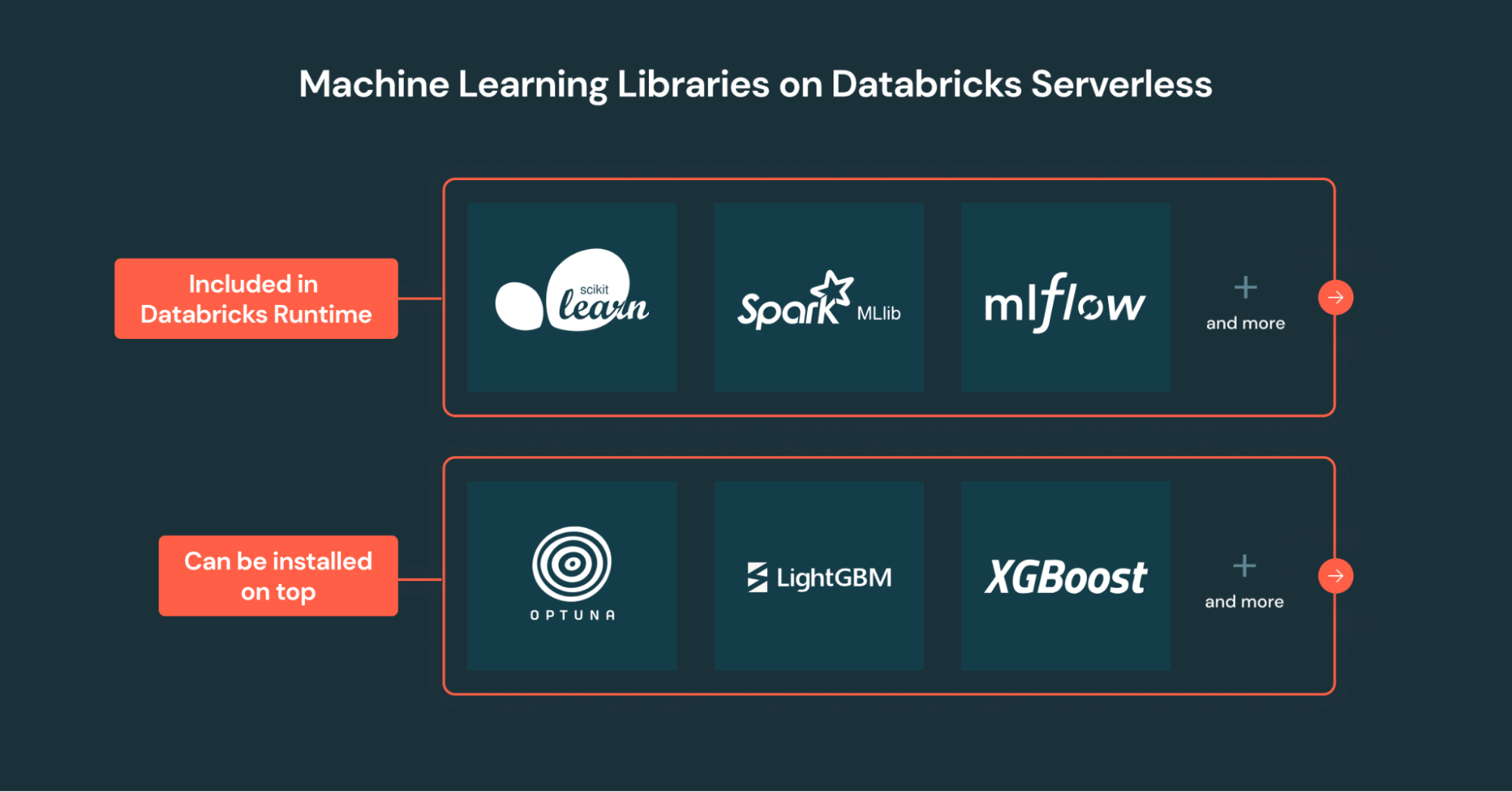
Apache Spark MLlib(Python)和Optuna在Databricks的无服务器笔记本和标准集群上公测,支持分布式机器学习,增强安全性和协作能力,提供统一的机器学习体验。
🎯
关键要点
- Apache Spark MLlib(Python)和Optuna在Databricks的无服务器笔记本和标准集群上公测。
- 支持分布式机器学习,增强安全性和协作能力。
- 无须专用集群即可实现性能、安全性和协作的结合。
- 之前,分布式机器学习工作负载只能在专用集群上运行,限制了多用户协作。
- 此次发布扩展了分布式机器学习能力,支持无服务器和标准集群。
- 增强功能与现有的单节点机器学习支持相辅相成,提供统一的机器学习体验。
- 用户现在可以在无服务器和标准集群上运行分布式机器学习工作负载。
- 支持使用Apache Spark MLlib(Python)训练分布式模型。
- 支持使用Optuna进行大规模超参数调优。
- 支持使用MLflow Spark跟踪和管理实验。
- 支持使用Joblib Spark分发Scikit-learn、LightGBM和XGBoost的单节点工作负载。
- 这些能力统一了机器学习体验,使团队能够无缝扩展从本地实验到分布式生产工作负载。
🏷️
标签
➡️
