
在Databricks中引入排序规则
内容提要
Databricks Runtime 16.1 现已支持多达 100 种语言特定的排序规则,使全球企业能够更高效地处理多语言和不一致的数据输入,简化数据操作并提升性能。
关键要点
-
Databricks Runtime 16.1 支持多达 100 种语言特定的排序规则,提升多语言数据处理效率。
-
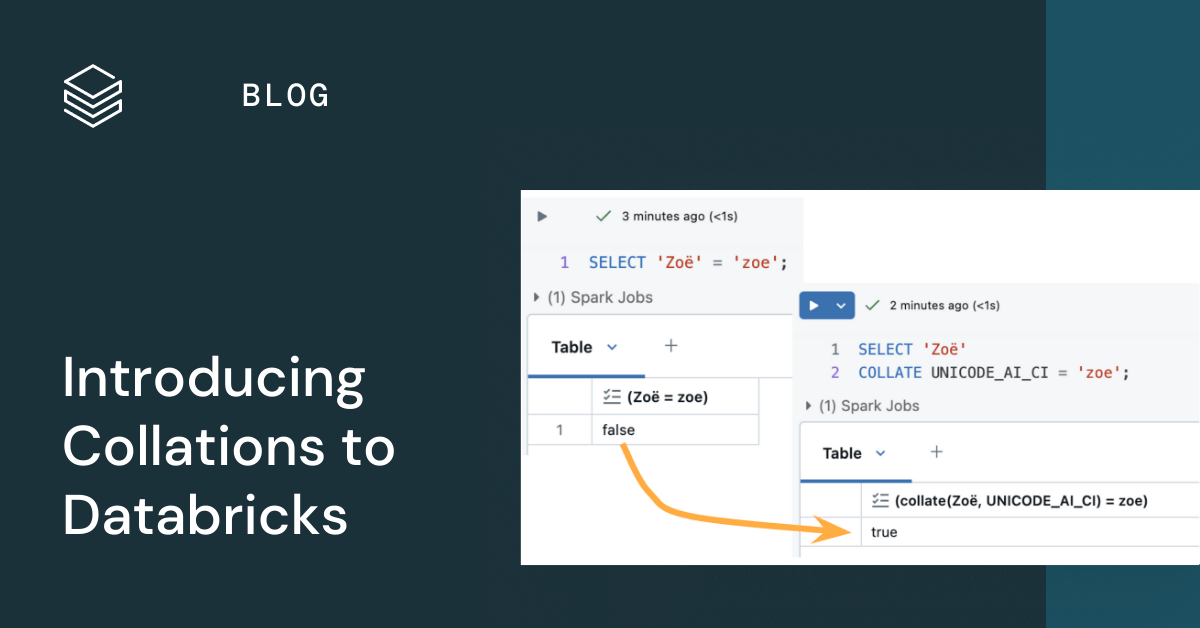
排序规则定义了文本排序和比较的规则,确保数据库能够尊重语言和大小写敏感性。
-
用户可以在数据工作流中选择超过 100 种语言特定的排序规则,简化数据操作。
-
排序规则支持所有数据操作,包括连接、排序、聚合等,且与 Delta 表原生支持兼容。
-
使用排序规则可以简化从遗留数据库系统的迁移,提升性能并简化代码。
-
排序规则与 Spark 功能紧密集成,支持多种字符串表达式的使用。
-
通过排序规则,可以实现不区分大小写的比较和按希腊字母排序等功能。
-
排序规则支持消除了进行成本高昂的操作的需要,提升了效率。
-
未来将支持在目录、模式或表级别设置排序规则,并即将推出 RTRIM 支持。
-
用户可以通过 Databricks 文档开始使用排序规则,了解更多关于 Databricks SQL 的信息。
延伸解读
排序规则的实用性
Databricks Runtime 16.1 引入的排序规则为多语言数据处理提供了强大的支持。用户可以根据特定语言的需求选择排序规则,确保数据操作符合语言习惯。这一功能特别适合需要处理多种语言的企业,能够显著提升数据处理的效率和准确性。
性能提升与迁移简化
使用排序规则可以减少在数据查询中进行大小写和重音敏感比较的开销,从而提高查询性能。对于从遗留数据库系统迁移的用户,排序规则的支持简化了迁移过程,减少了代码复杂性,使得数据迁移更加顺畅。
未来功能展望
Databricks 计划在未来支持在目录、模式或表级别设置排序规则,并引入 RTRIM 功能。这些新功能将进一步增强用户在数据管理中的灵活性和便利性,值得用户关注即将发布的更新。
延伸问答
Databricks Runtime 16.1 支持多少种排序规则?
Databricks Runtime 16.1 支持多达 100 种语言特定的排序规则。
排序规则在数据处理中的作用是什么?
排序规则定义了文本排序和比较的规则,确保数据库能够尊重语言和大小写敏感性。
如何在数据工作流中使用排序规则?
用户可以在数据工作流中选择超过 100 种语言特定的排序规则,以简化数据操作。
排序规则如何提高性能?
使用排序规则可以消除进行成本高昂的操作的需要,从而提升效率。
未来的排序规则功能有哪些计划?
未来将支持在目录、模式或表级别设置排序规则,并即将推出 RTRIM 支持。
如何开始使用排序规则?
用户可以通过 Databricks 文档开始使用排序规则,了解更多关于 Databricks SQL 的信息。
