
在 Kubernetes 中 Autoscale LLM 的实践
内容提要
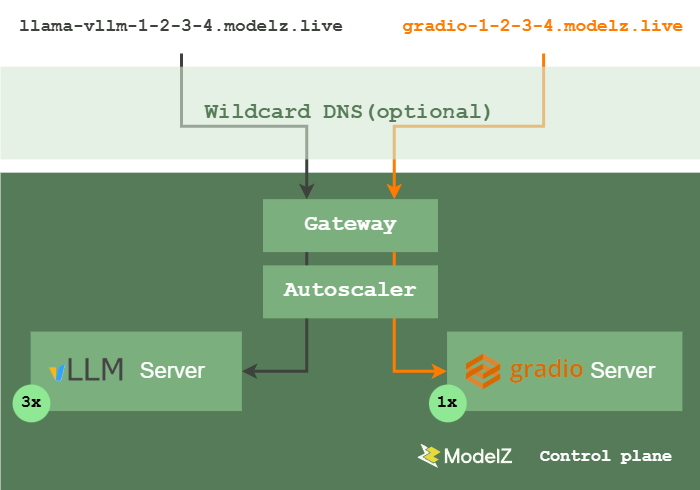
本文介绍了2023年推出的无服务器大型语言模型推理平台ModelZ及其核心组件OpenModelZ,重点讨论了在Kubernetes上部署LLMs的挑战,如冷启动、自动扩展和负载均衡。用户可通过简单API上传模型,系统自动管理推理服务的生命周期,优化模型和镜像加载以提升性能。
关键要点
-
ModelZ是一个无服务器大型语言模型推理平台,核心组件为OpenModelZ。
-
在Kubernetes上部署LLMs面临冷启动、自动扩展和负载均衡等挑战。
-
用户通过简单API上传模型,系统自动管理推理服务的生命周期。
-
冷启动问题主要由镜像加载和模型参数加载造成,需要优化以提升用户体验。
-
模型加载过程可以通过集群内部署缓存来加速,避免重复下载。
-
镜像加载可以使用GCP image streaming等技术来加速,理想情况下应采用混合加载方式。
-
Autoscaler根据用户设置和当前负载情况调整副本数,确保服务的自动扩缩容。
-
负载均衡目前采用简单的轮询方式,未来可能需要更复杂的策略以应对kvcache的挑战。
延伸解读
冷启动优化的重要性
在Kubernetes上部署大型语言模型时,冷启动问题尤为突出。模型参数的加载时间可能导致用户体验不佳,因此优化冷启动过程至关重要。通过在集群内部署缓存,可以显著减少模型的重复下载时间,从而提升整体性能。
自动扩缩容的挑战
尽管Autoscaler能够根据负载情况自动调整副本数,但在没有空闲节点的情况下,扩容可能会面临延迟。这要求系统设计中考虑预留GPU节点池,以减少扩容时的等待时间,确保服务的高可用性。
负载均衡策略的未来
当前的负载均衡方案采用简单的轮询方式,但随着kvcache等新技术的引入,未来可能需要更复杂的负载均衡策略。如何在对话场景中有效管理状态,将是提升LLM推理服务性能的关键。
延伸问答
ModelZ是什么?
ModelZ是一个无服务器大型语言模型推理平台,核心组件为OpenModelZ。
在Kubernetes上部署LLMs面临哪些挑战?
在Kubernetes上部署LLMs面临冷启动、自动扩展和负载均衡等挑战。
如何优化冷启动问题?
冷启动问题可以通过优化镜像加载和模型参数加载来加速,使用集群内部署缓存可以避免重复下载。
Autoscaler是如何工作的?
Autoscaler根据用户设置的扩缩容策略和当前负载情况来调整副本数,确保服务的自动扩缩容。
负载均衡目前采用什么方式?
目前负载均衡采用简单的轮询方式,未来可能需要更复杂的策略以应对kvcache的挑战。
用户如何使用ModelZ进行模型上传?
用户可以通过简单API上传模型,系统会自动管理推理服务的生命周期。
