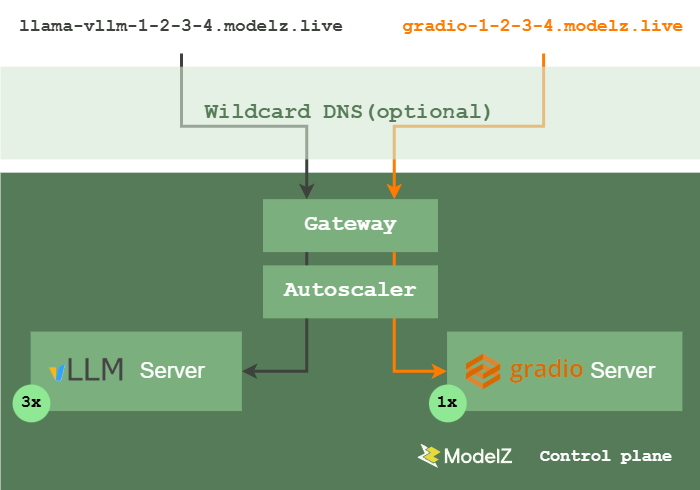
使用Amazon SageMaker Hyperpod Cluster部署whisper模型
亚马逊AWS官方博客
·
.png)
Modular:BentoML与Modular合并
Modular Blog
·
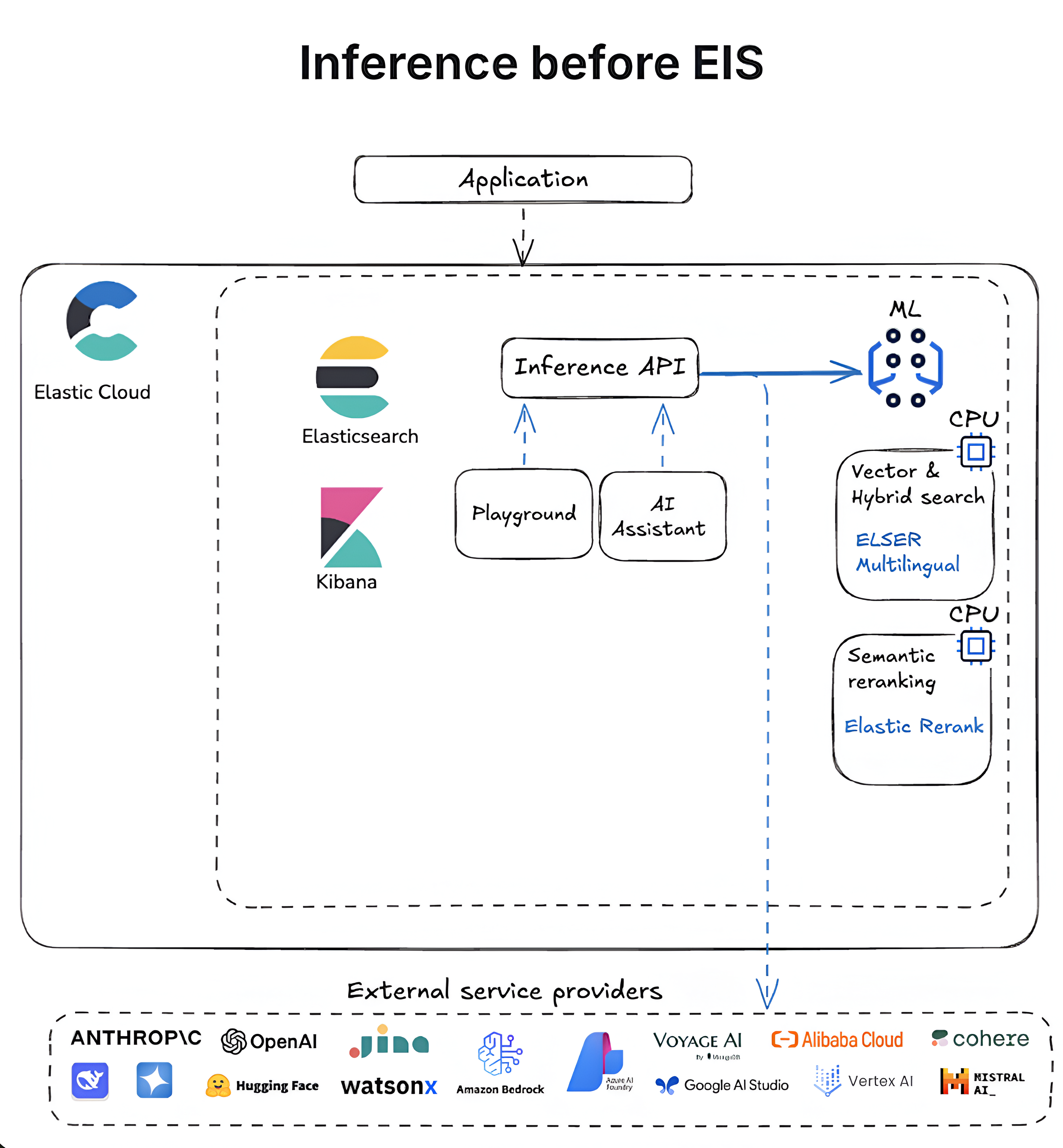
GPU 狂飙!Elastic 推理服务 (EIS):适用于 Elasticsearch 的 GPU 加速推理
Elastic Blog
·