

vLLM Triton 注意力后端深度解析
💡
原文英文,约2000词,阅读约需7分钟。
📝
内容提要
本文介绍了IBM研究、红帽和AMD团队开发的vLLM Triton注意力后端,旨在实现跨GPU平台的高性能。Triton是一种特定领域语言,支持用Python编写高效的GPU内核,兼容多种模型和硬件。通过优化内核设计和微基准测试,Triton后端在AMD、NVIDIA和Intel平台上表现优异,成为默认的注意力后端。
🎯
关键要点
- IBM研究、红帽和AMD团队开发了vLLM Triton注意力后端,旨在实现跨GPU平台的高性能。
- Triton是一种特定领域语言,支持用Python编写高效的GPU内核,兼容多种模型和硬件。
- Triton后端通过优化内核设计和微基准测试,在AMD、NVIDIA和Intel平台上表现优异。
- vLLM旨在提供最佳的推理性能,支持多种加速器和模型架构。
- Triton后端是vLLM的默认注意力后端,能够在不同GPU上运行相同的源代码。
- Triton注意力后端支持多种特性,如ALiBi sqrt和小头尺寸模型的注意力。
- 开发Triton注意力后端时,首先在vLLM外部实现内核,并通过微基准测试进行评估。
- Paged attention通过分页KV缓存以内存高效的方式实现注意力。
- 优化tile大小和并行化策略是提高性能的关键。
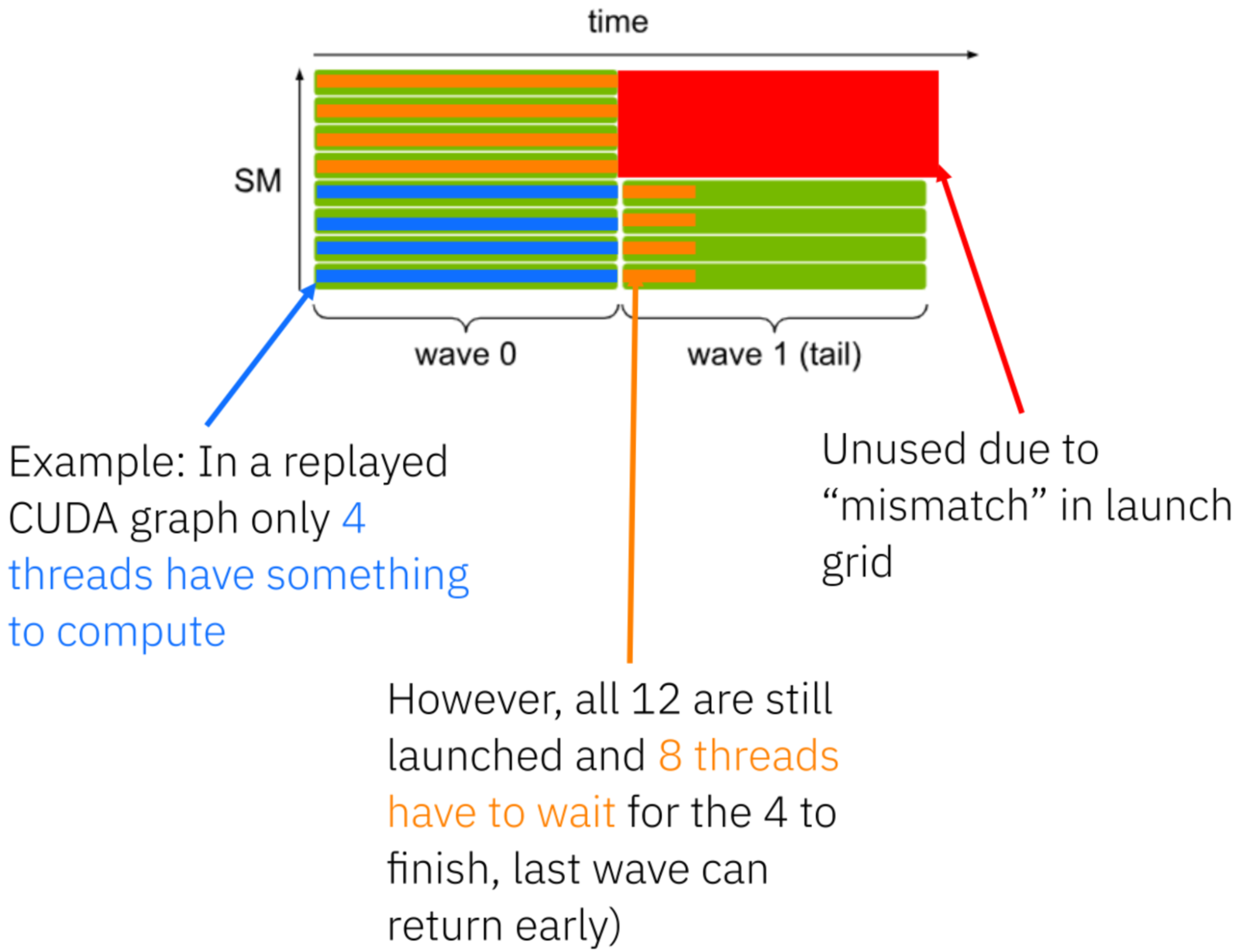
- 基于CUDA图的持久内核设计提高了效率,减少了内核启动开销。
- 基准测试结果显示,Triton注意力后端在NVIDIA和AMD平台上表现出色,性能接近或超过专门实现。
- Helion是PyTorch团队的新领域特定语言,已在实验中实现了简化的paged attention内核,初步结果良好。
- Triton注意力后端展示了使用单一可移植内核实现先进注意力性能的可能性。
➡️
