
vLLM TPU:支持PyTorch和JAX的新统一后端
内容提要
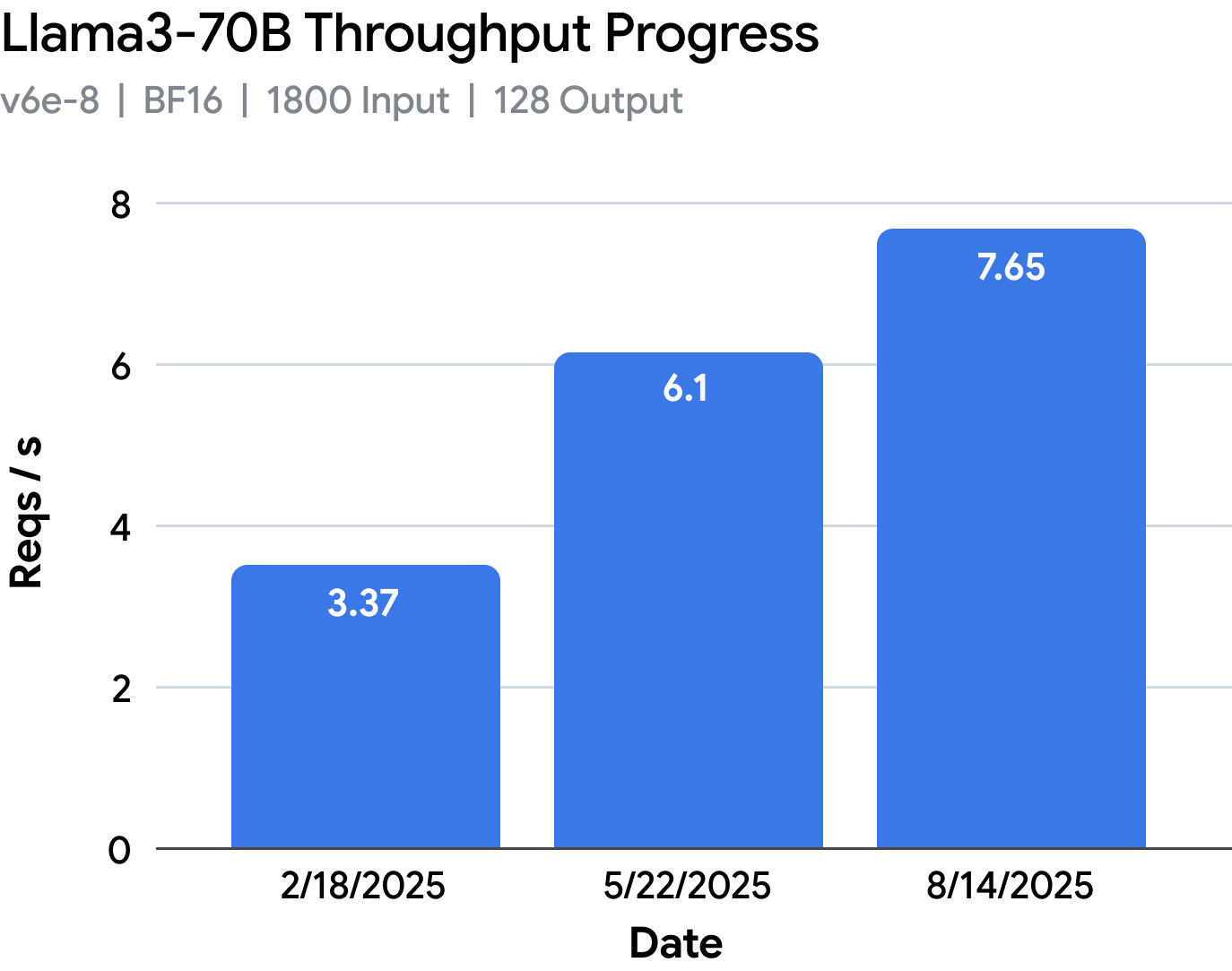
vLLM TPU通过tpu-inference插件整合JAX和PyTorch,显著提升性能和模型支持。新设计优化了TPU性能,支持多种模型,简化开发流程。RPA v3内核增强灵活性和效率,SPMD模型提升性能,整体性能较2025年原型提升近5倍,推动开源TPU推理的发展。
关键要点
-
vLLM TPU通过tpu-inference插件整合JAX和PyTorch,提升性能和模型支持。
-
新设计优化TPU性能,支持多种模型,简化开发流程。
-
RPA v3内核增强灵活性和效率,支持更多模型规格和量化类型。
-
整体性能较2025年原型提升近5倍,推动开源TPU推理的发展。
-
SPMD成为vLLM TPU的默认编程模型,支持更高级的优化。
-
vLLM TPU将定期发布新版本,持续改进模型覆盖和可用性。
-
支持的模型包括密集模型和多模态模型,未来将增加更多功能。
-
感谢vLLM社区的支持,特别是对TPU V0实现的贡献。
延伸解读
TPU性能提升的意义
vLLM TPU的性能提升近5倍,意味着开发者在处理复杂模型时可以获得更高的效率。这种显著的性能改进将推动更多开源项目的开发,尤其是在需要高计算能力的深度学习领域。开发者应关注如何利用这一新平台来优化现有模型,提升推理速度。
统一后端的优势
通过将JAX和PyTorch整合到一个统一的后端,vLLM TPU为开发者提供了更大的灵活性。无论是使用哪种框架,开发者都可以享受到相似的性能和用户体验。这种设计简化了开发流程,降低了学习曲线,使得新用户更容易上手。
RPA v3的灵活性与性能
RPA v3内核的推出不仅提升了TPU的性能,还增强了对多种模型规格的支持。其灵活性使得开发者能够更好地应对不同的应用场景,尤其是在处理复杂的多模态模型时。关注RPA v3的使用,可以帮助开发者在实际应用中获得更好的性能表现。
延伸问答
vLLM TPU的主要功能是什么?
vLLM TPU通过tpu-inference插件整合JAX和PyTorch,提升性能和模型支持,简化开发流程。
RPA v3内核相比于RPA v2有哪些改进?
RPA v3支持更多模型规格和量化类型,提升了管道效率,并且在性能上比RPA v2提高了约10%。
vLLM TPU如何支持PyTorch和JAX模型?
vLLM TPU通过统一的JAX→XLA降低路径,支持PyTorch和JAX模型,使得PyTorch模型在TPU上运行时无需额外代码更改。
SPMD编程模型的优势是什么?
SPMD编程模型允许在单个设备上编写代码,XLA编译器自动分割模型和张量,优化执行效率,支持更高级的优化。
vLLM TPU的性能提升幅度是多少?
vLLM TPU的整体性能较2025年原型提升近5倍。
vLLM TPU未来的更新计划是什么?
vLLM TPU将定期发布新版本,持续改进模型覆盖和可用性,增加更多功能。
