
ZipNN:一种针对神经网络的新型无损压缩方法
内容提要
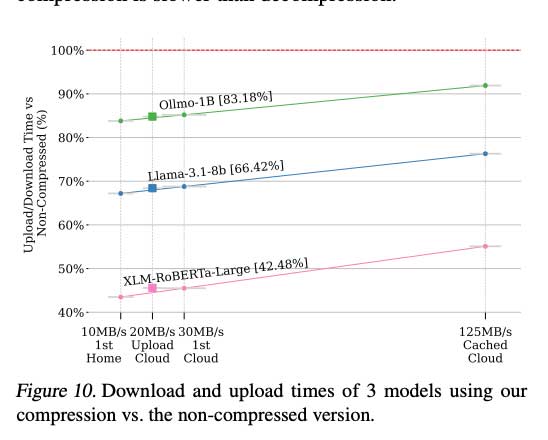
大型语言模型(LLM)面临存储、内存和网络带宽的瓶颈。模型压缩技术如修剪、知识提炼和量化旨在减小模型体积。ZipNN是一种新型无损压缩技术,能够将神经网络模型压缩高达33%,同时提升性能和速度,显著减少网络流量。研究表明,针对模型架构的定制压缩有效解决了存储和通信的低效率问题。
关键要点
-
大型语言模型(LLM)面临存储、内存和网络带宽的瓶颈。
-
模型压缩技术包括修剪、知识提炼和量化,旨在减小模型体积。
-
ZipNN是一种新型无损压缩技术,能够将神经网络模型压缩高达33%。
-
ZipNN在性能和速度上优于普通压缩技术,压缩和解压速度提高了62%。
-
ZipNN有潜力每月为大型模型分发平台节省1EB的网络流量。
-
ZipNN的架构支持高效、并行的神经网络模型压缩,适合多核心GPU架构。
-
研究表明,模型架构中存在大量冗余,可以通过定制压缩技术解决。
-
尽管大型模型趋势明显,但可以在不损害模型完整性的情况下节省空间和带宽。
延伸解读
模型压缩的必要性
随着大型语言模型的快速发展,存储和带宽的瓶颈问题愈发明显。ZipNN作为一种新型无损压缩技术,能够有效减小模型体积,提升性能,帮助解决这些基础设施挑战。对于需要频繁更新和传输模型的应用场景,ZipNN的优势尤为突出。
ZipNN的技术优势
ZipNN不仅在压缩率上表现出色,还在解压速度上提高了62%。这种高效的压缩方式特别适合多核心GPU架构,能够充分利用并行处理的优势,提升整体计算效率。对于开发者而言,选择ZipNN可以在保证模型性能的同时,显著降低资源消耗。
压缩技术的局限性
尽管ZipNN在压缩效果上表现优异,但仍需注意模型压缩可能带来的信息损失风险。与传统的修剪和量化方法相比,ZipNN的无损特性是其一大优势,但在特定情况下,模型的复杂性和性能可能仍会受到影响。
延伸问答
ZipNN是什么?
ZipNN是一种新型无损压缩技术,专为神经网络设计,能够将模型压缩高达33%。
ZipNN与其他模型压缩技术相比有什么优势?
ZipNN在性能和速度上优于普通压缩技术,压缩和解压速度提高了62%。
ZipNN如何影响大型语言模型的网络流量?
ZipNN有潜力每月为大型模型分发平台节省1EB的网络流量。
ZipNN的架构设计有什么特点?
ZipNN的架构支持高效、并行的模型压缩,特别适合多核心GPU架构。
ZipNN的实验评估是在什么环境下进行的?
ZipNN的实验评估是在一台拥有10个内核和64GB RAM的Apple M1 Max机器上进行的。
ZipNN的压缩策略是如何工作的?
ZipNN的压缩策略在块级别和字节组级别上运行,允许独立处理模型段。
