
Liquid AI发布LFM2.5:专为真实设备端智能体打造的紧凑型 AI 模型系列
内容提要
Liquid AI推出LFM2.5,基于LFM2架构,专注于设备和边缘部署,支持多种语言和视觉模型。在多个基准测试中表现优异,尤其在文本和日语任务上超越同类模型,适用于多模态应用。
关键要点
-
Liquid AI推出LFM2.5,基于LFM2架构,专注于设备和边缘部署。
-
LFM2.5系列包括LFM2.5-1.2B-Base和LFM2.5-1.2B-Instruct,支持多种语言和视觉模型。
-
模型以开源权重形式发布在Hugging Face上,并通过LEAP平台对外开放。
-
LFM2.5的预训练规模从10T扩展到28T个token,采用混合架构以实现高效内存推理。
-
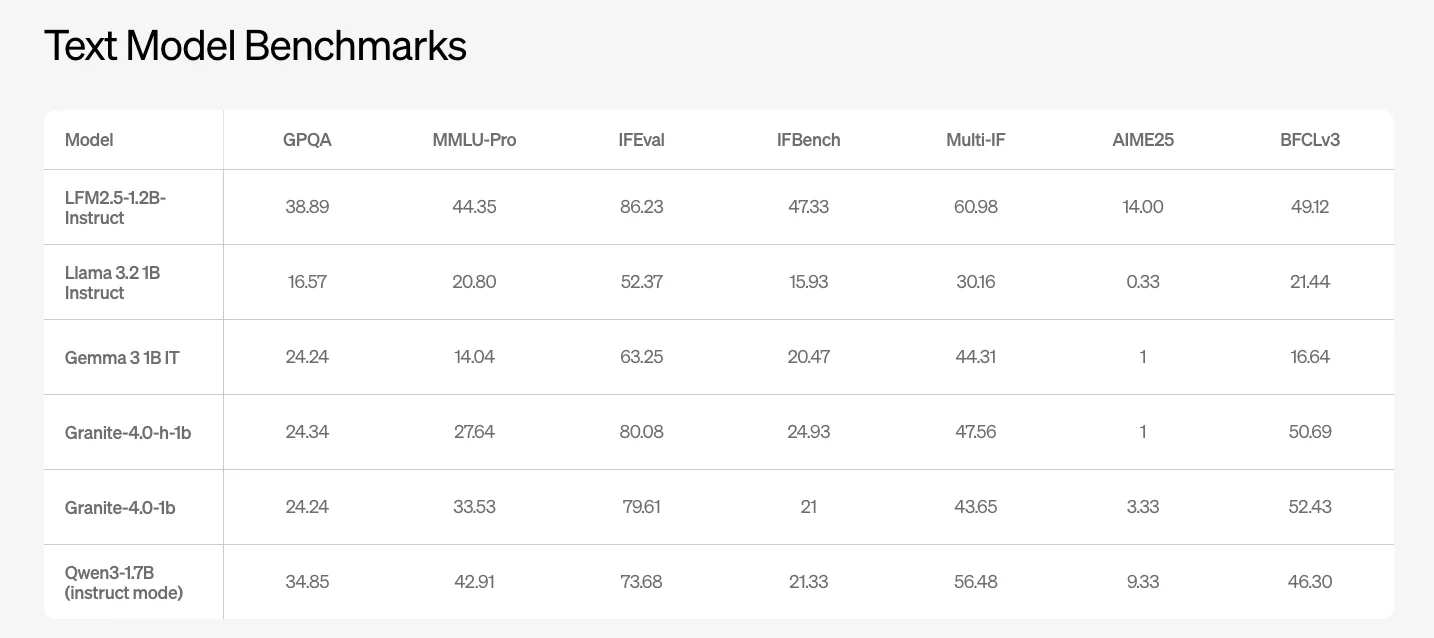
LFM2.5-1.2B-Instruct在多个基准测试中表现优异,GPQA得分为38.89,MMLU Pro得分为44.35。
-
LFM2.5-1.2B-JP是日语优化版本,在日语任务上优于通用指令模型。
-
LFM2.5-VL-1.6B是视觉语言模型,优化用于文档理解和多图像推理。
-
LFM2.5-Audio-1.5B是音频语言模型,支持文本和音频的输入输出,具有低延迟生成模式。
-
该系列模型涵盖基础版、指令版、日语版、视觉语言版和音频语言版,均以开放权重形式发布。
延伸解读
多模态应用的潜力
LFM2.5系列模型的多模态特性使其在边缘设备上具有广泛的应用潜力。特别是视觉语言模型和音频语言模型的结合,能够支持复杂的用户交互场景,如实时语音助手和文档理解。这种多样性为开发者提供了更多的创新空间,适应不同的市场需求。
日语优化的重要性
LFM2.5-1.2B-JP专为日语任务优化,显示出在本地化应用中的优势。随着全球市场对多语言支持的需求增加,具备针对特定语言优化的模型将更具竞争力,尤其是在日本市场,这可能为相关企业带来更高的用户满意度和市场份额。
开源与社区支持
LFM2.5系列以开源权重形式发布,意味着开发者可以自由使用和修改。这种开放性不仅促进了技术的快速迭代,也鼓励了社区的参与和反馈,有助于模型的持续优化和应用场景的扩展。开发者应关注社区动态,以获取最新的使用案例和最佳实践。
延伸问答
LFM2.5模型的主要特点是什么?
LFM2.5模型专注于设备和边缘部署,支持多种语言和视觉模型,预训练规模从10T扩展到28T个token,采用混合架构以实现高效内存推理。
LFM2.5-1.2B-Instruct在基准测试中的表现如何?
LFM2.5-1.2B-Instruct在GPQA测试中得分为38.89,在MMLU Pro测试中得分为44.35,表现优于其他同类模型。
LFM2.5系列模型有哪些不同的版本?
LFM2.5系列包括基础版、指令版、日语版、视觉语言版和音频语言版,满足不同应用需求。
LFM2.5-VL-1.6B模型的应用场景是什么?
LFM2.5-VL-1.6B模型优化用于文档理解、用户界面阅读和多图像推理等实际应用任务。
LFM2.5-Audio-1.5B模型的生成模式有哪些?
LFM2.5-Audio-1.5B模型支持交错生成模式和顺序生成模式,适用于实时语音对话和自动语音识别等任务。
LFM2.5模型的开源发布平台是什么?
LFM2.5模型以开源权重的形式发布在Hugging Face上,并通过LEAP平台对外开放。
