
开放湖仓的下一个时代:Databricks上Apache Iceberg™ v3公测
💡
原文英文,约1100词,阅读约需4分钟。
📝
内容提要
Databricks的Iceberg v3进入公测,支持增量数据处理和半结构化数据分析,简化数据管道。新特性包括行血统、删除向量和VARIANT类型,提升性能,支持多引擎互操作性,优化数据治理,降低维护成本。
🎯
关键要点
-
Databricks的Iceberg v3进入公测,支持增量数据处理和半结构化数据分析。
-
Iceberg v3引入行血统、删除向量和VARIANT类型,提升性能和互操作性。
-
行血统帮助快速识别数据变化,删除向量提高数据操作性能。
-
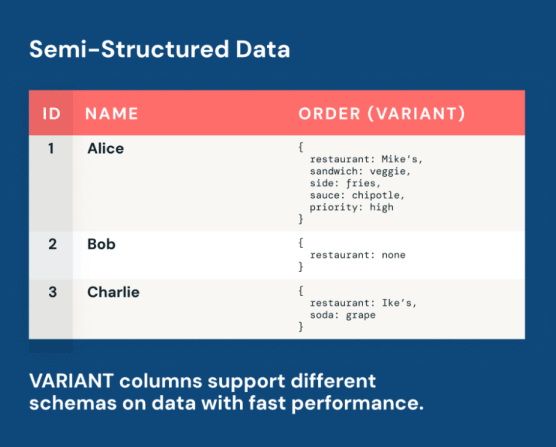
VARIANT类型允许半结构化数据与关系型列共存,简化数据处理。
-
Unity Catalog实现多引擎和多目录的互操作性,优化数据治理。
-
Delta Lake与Iceberg的互操作性增强,简化数据管理。
-
Databricks提供自动化性能优化,减少操作开销。
❓
延伸问答
Iceberg v3的主要新特性是什么?
Iceberg v3引入了行血统、删除向量和VARIANT类型,支持增量数据处理和半结构化数据分析,提升性能和互操作性。
行血统和删除向量如何提高数据处理性能?
行血统帮助快速识别数据变化,而删除向量允许逻辑删除行而无需重写数据文件,从而使数据操作性能提高至传统方法的10倍。
VARIANT类型在Iceberg v3中有什么作用?
VARIANT类型允许半结构化数据与关系型列共存,简化数据处理,无需进行模式迁移,支持直接查询。
Unity Catalog如何优化数据治理?
Unity Catalog实现跨目录和引擎的互操作性,支持细粒度访问控制,简化数据治理和监控。
Databricks如何实现Delta Lake与Iceberg的互操作性?
Databricks通过UniForm实现Delta Lake与Iceberg的互操作性,允许在Delta Lake中写入数据并在Iceberg中读取,消除数据复制的需要。
Databricks在性能优化方面提供了哪些自动化功能?
Databricks结合预测优化、自动液体聚类和Unity Catalog,实现性能和布局优化,减少操作开销,提升数据可移植性。
➡️
