
变换器架构如何驱动现代大型语言模型
内容提要
到2026年,AI模型的瓶颈将是上下文而非模型本身。AI代理需从多种数据源提取信息,缺乏关键上下文会导致响应失效。上下文引擎将通过存储和索引结构化与非结构化数据,实现更快的响应和更低的成本。现代大型语言模型(LLM)如GPT和Claude利用变换器架构和注意力机制生成连贯文本。
关键要点
-
到2026年,AI模型的瓶颈将是上下文而非模型本身。
-
AI代理需从多种数据源提取信息,缺乏关键上下文会导致响应失效。
-
上下文引擎将通过存储和索引结构化与非结构化数据,实现更快的响应和更低的成本。
-
现代大型语言模型(LLM)如GPT和Claude利用变换器架构和注意力机制生成连贯文本。
-
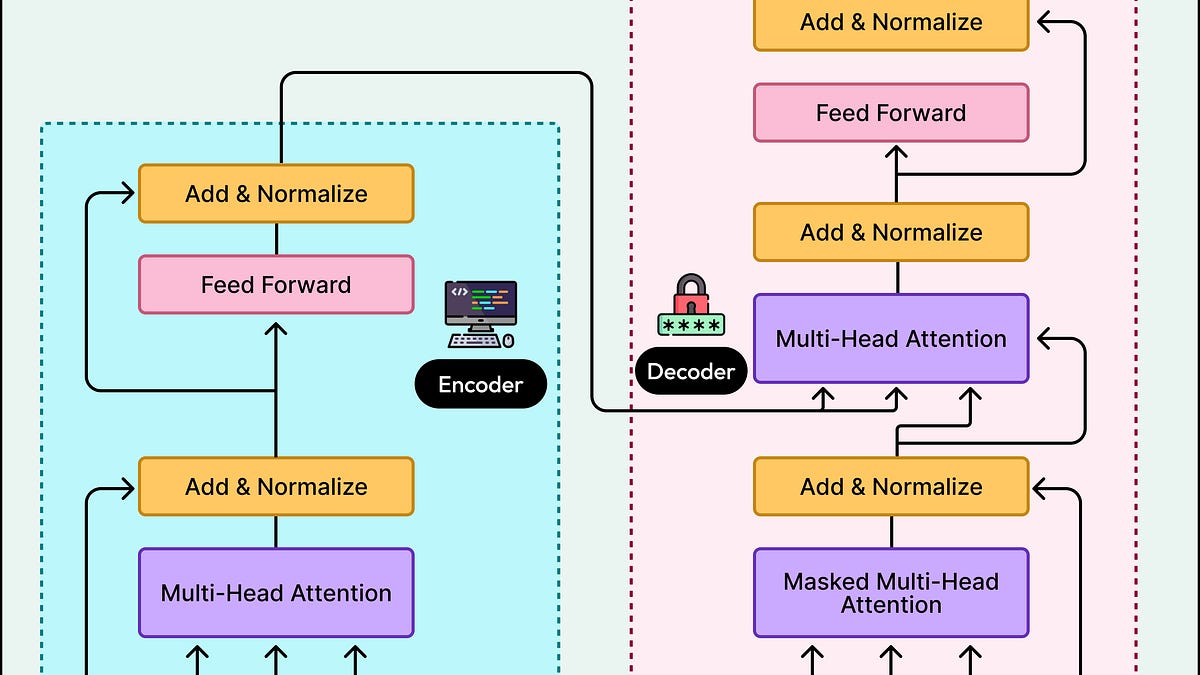
变换器架构由嵌入层、多层变换器和输出层组成。
-
模型通过标记化将文本转换为基本单位,称为标记。
-
标记被映射到向量,形成语义空间,相关概念聚集在一起。
-
位置嵌入用于提供单词顺序信息,结合词义和上下文。
-
注意力机制使模型能够根据上下文加权组合信息,提取重要的单词关系。
-
每层变换器学习不同的语言模式,从基本语法到抽象意义。
-
生成过程是自回归的,每个输出依赖于之前的输出。
-
训练和推理是变换器的两种不同模式,训练过程中模型学习语言模式,推理时使用已学习的权重进行预测。
-
变换器架构通过将文本转换为数值表示,使用注意力机制捕捉单词之间的关系,堆叠多层以学习抽象模式,从而生成连贯的文本。
延伸解读
上下文的重要性
随着AI技术的发展,模型的瓶颈逐渐转向上下文的获取与处理。缺乏关键上下文信息可能导致AI代理的响应失效,因此在设计AI应用时,开发者需要重视上下文引擎的构建,以确保信息的准确提取和有效利用。
变换器架构的优势
变换器架构通过并行处理和注意力机制,使得大型语言模型能够捕捉复杂的语言关系。这种架构不仅提高了文本生成的连贯性,还能在多层次上学习语言模式,适应不同的上下文需求。理解这一点有助于开发更高效的AI应用。
训练与推理的区别
在变换器模型中,训练和推理是两个截然不同的过程。训练阶段需要大量数据和计算资源来调整模型权重,而推理阶段则是利用已学习的权重进行预测。了解这一区别有助于更好地评估模型的性能和应用场景。
延伸问答
变换器架构的主要组成部分是什么?
变换器架构主要由嵌入层、多层变换器和输出层组成。
上下文引擎在AI模型中有什么作用?
上下文引擎通过存储和索引结构化与非结构化数据,实现更快的响应和更低的成本。
大型语言模型如何处理文本生成?
大型语言模型通过自回归生成过程,每个输出依赖于之前的输出,逐步生成连贯的文本。
注意力机制在变换器架构中如何工作?
注意力机制通过比较查询与所有可能答案的键,生成加权组合的值,从而提取重要的单词关系。
变换器架构如何处理单词顺序信息?
变换器架构通过位置嵌入提供单词顺序信息,结合词义和上下文。
训练和推理在变换器架构中有什么区别?
训练过程中模型学习语言模式,推理时使用已学习的权重进行预测,且不再更新权重。
