
LangChain与增强生成技术(RAG)的最佳实践
内容提要
本文介绍了LangChain和增强生成技术(RAG)的最佳实践,重点在于如何利用向量存储构建语言模型应用。内容涵盖数据加载、文本分割、向量存储、检索方法(如相似性搜索和最大边际相关性),以及如何通过大型语言模型(LLM)生成准确回答。提供示例代码,帮助读者提高查询的准确性和效率。
关键要点
-
LangChain是一个开源开发框架,用于构建大型语言模型应用。
-
RAG过程依赖于向量存储加载和检索增强生成。
-
数据加载器可处理不同格式的数据,包括PDF和网页。
-
文本分割器用于将文档分割成较小的块,以提高计算效率和模型的泛化能力。
-
向量存储用于存储每个文本块,并在查询时返回最相似的向量。
-
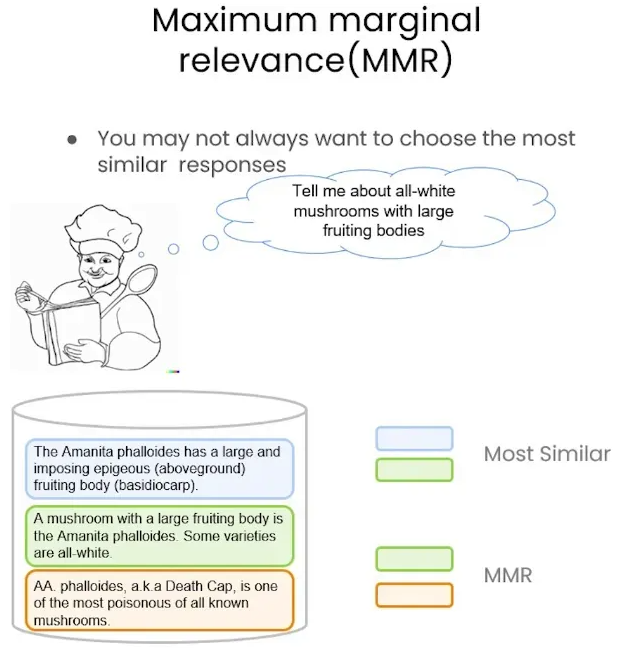
相似性搜索和最大边际相关性(MMR)是检索方法,用于提高查询的准确性和多样性。
-
元数据可以用于过滤检索结果,从而提高查询的准确性。
-
LLM辅助检索使用语言模型自动解析句子语义,提取过滤信息。
-
压缩检索机制通过提取相关部分来减少资源浪费。
-
检索问答链结合检索结果和生成能力,提高答案的准确性和实时更新知识库的能力。
延伸解读
LangChain的应用场景
LangChain作为一个开源框架,适用于构建各种大型语言模型应用。它的灵活性使得开发者可以根据不同的数据源和需求,定制数据加载、文本处理和检索机制。这种适应性对于需要处理多种格式数据的项目尤为重要,尤其是在信息快速变化的领域,如金融和医疗。
RAG的优势与挑战
增强生成技术(RAG)通过结合向量存储和检索机制,显著提高了查询的准确性和效率。然而,实施RAG时需注意数据的质量和多样性,过于依赖相似性搜索可能导致信息的单一性。因此,在设计检索策略时,平衡相关性与多样性是关键。
文本分割的重要性
在处理大型文档时,文本分割器的使用至关重要。通过将文档分割成较小的块,可以提高计算效率和模型的泛化能力。然而,分割点的选择需谨慎,以避免信息丢失。开发者应根据具体应用场景,选择合适的分割策略,以确保信息的完整性和上下文的连贯性。
延伸问答
LangChain是什么?
LangChain是一个开源开发框架,用于构建大型语言模型应用。
RAG过程的主要步骤是什么?
RAG过程包括向量存储加载和检索增强生成,用户输入后系统从向量存储中检索相关文档片段,并结合上下文生成答案。
如何提高查询的准确性?
可以通过使用相似性搜索和最大边际相关性(MMR)等检索方法,以及利用元数据过滤检索结果来提高查询的准确性。
文本分割器的作用是什么?
文本分割器用于将文档分割成较小的块,以提高计算效率和模型的泛化能力。
什么是最大边际相关性(MMR)?
最大边际相关性(MMR)是一种检索方法,旨在平衡检索结果的相关性和多样性,避免重复信息。
如何使用LangChain进行文档加载?
可以使用不同格式的数据加载器,如PDF和网页加载器,来处理和加载文档。
