
如何使用Prometheus高效检测大规模异常
内容提要
Grafana Labs开发了一种基于PromQL的异常检测框架,适用于内部调试和Grafana Cloud应用。该框架无需外部系统,兼容Prometheus,适合大规模操作。通过平均值和标准差建立基线,解决极端异常值和低灵敏度问题,并考虑长期模式。用户可在Prometheus中添加记录和警报规则,适用于任何指标,有助于快速解决问题,并可与SLO警报结合进行根本原因分析。
关键要点
-
Grafana Labs开发了一种基于PromQL的异常检测框架,适用于内部调试和Grafana Cloud应用。
-
该框架无需外部系统,兼容Prometheus,适合大规模操作。
-
通过平均值和标准差建立基线,解决极端异常值和低灵敏度问题,并考虑长期模式。
-
用户可在Prometheus中添加记录和警报规则,适用于任何指标,有助于快速解决问题。
-
框架的设计原则包括无外部依赖、兼容性、可扩展性和可解释性。
-
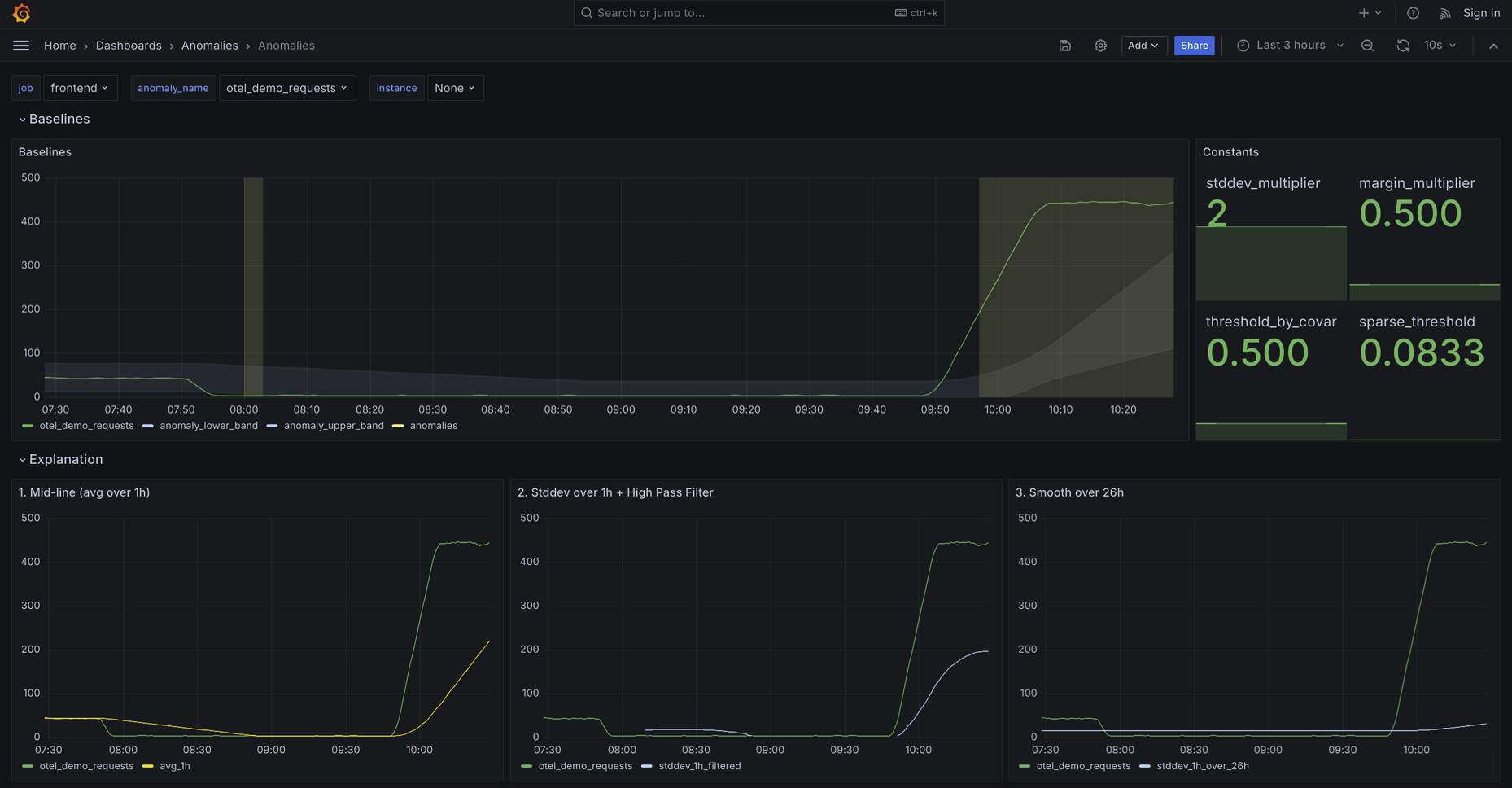
初步尝试使用z-score公式建立基线,定义异常行为的上下限。
-
在生产中遇到极端异常值、低灵敏度和不连续性等挑战,并通过平滑函数和过滤规则进行调整。
-
引入长期模式检测以适应季节性变化,确保准确预测未来行为。
-
用户可以通过添加记录和警报规则来使用该框架,并在GitHub上找到相关资源。
-
异常检测提供上下文,但需要与SLO警报结合进行根本原因分析,以提高数据的可操作性。
延伸解读
异常检测框架的优势
Grafana Labs开发的基于PromQL的异常检测框架,具有无外部依赖、兼容性和可扩展性等优点。这使得用户能够在大规模操作中高效监测异常,尤其适合需要快速响应的生产环境。通过使用Prometheus的内置功能,用户可以轻松集成该框架,降低了技术门槛。
建立基线的重要性
在异常检测中,建立准确的基线至关重要。使用平均值和标准差的公式可以帮助定义正常行为的上下限,从而识别异常。然而,选择合适的时间窗口和调整灵敏度参数是关键,这直接影响到检测的准确性和有效性。
应对极端异常值的挑战
在生产环境中,极端异常值可能导致检测系统失效。Grafana Labs通过引入平滑函数和过滤规则来控制带宽的扩展速度,从而提高系统的稳定性和灵敏度。这种方法有效地减少了误报,确保了异常检测的可靠性。
结合SLO警报进行根本原因分析
虽然异常检测提供了重要的上下文信息,但仅凭异常信号不足以判断问题的严重性。将异常检测与SLO警报结合,可以更有效地进行根本原因分析,帮助团队快速定位和解决问题,提高系统的可操作性。
延伸问答
Prometheus异常检测框架的主要功能是什么?
该框架基于PromQL,旨在高效检测大规模异常,适用于内部调试和Grafana Cloud应用。
如何在Prometheus中建立异常检测的基线?
通过平均值和标准差建立基线,使用公式:基线 = 平均值 ± 标准差 * 乘数。
该框架如何解决极端异常值的问题?
通过引入平滑函数来控制带宽扩展速度,从而减少极端异常值对检测的影响。
如何提高异常检测的灵敏度?
通过调整标准差的计算和过滤低变异性时期来提高灵敏度,确保检测到正常波动。
如何将异常检测与SLO警报结合使用?
将异常检测结果与预设的SLO警报关联,以便进行根本原因分析和加速故障排除。
用户如何在Prometheus中使用该异常检测框架?
用户只需添加记录和警报规则到Prometheus实例,并标记指标即可使用该框架。
