
工程师之夜系列分享第三十九篇:Kafka、RocketMQ、JMQ 存储架构深度对比
内容提要
本文比较了三款主流消息队列(Kafka、RocketMQ、JMQ)的存储架构,分析了它们的存储模型、数据组织和索引设计。Kafka以分区日志流为核心,RocketMQ采用分离式设计,JMQ结合了两者的优点,适应京东场景,为技术选型提供参考。
关键要点
-
消息队列的存储架构影响可靠性、吞吐量和延迟性能。
-
Kafka、RocketMQ和JMQ是三款主流消息队列,各有特点。
-
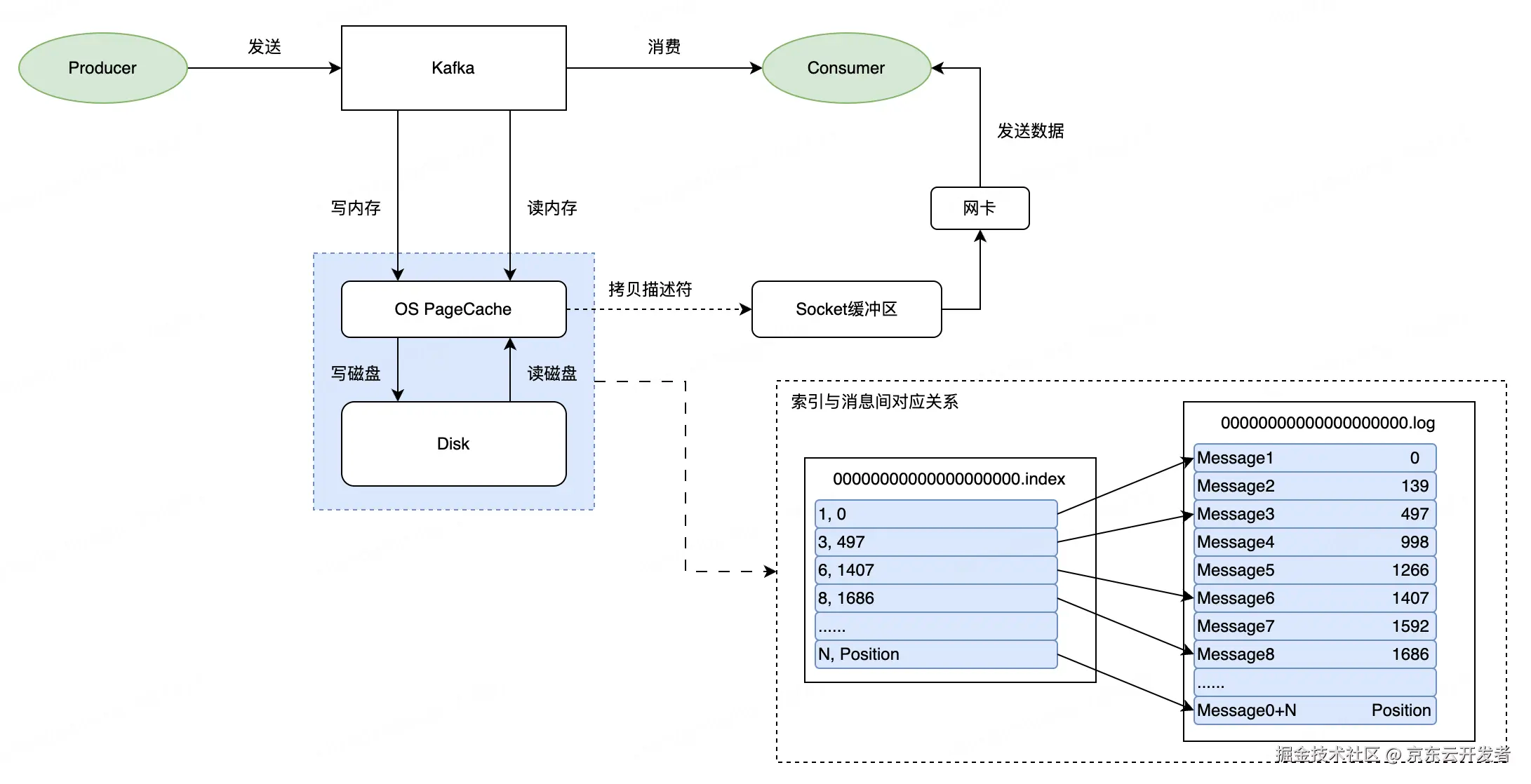
Kafka的核心存储模型是分区日志流,采用主题和分区的设计。
-
Kafka通过分区提高性能,支持多线程并行处理。
-
Kafka的数据组织采用分段日志文件和索引文件。
-
Kafka的消息读写过程依赖于内存映射和顺序写入。
-
RocketMQ采用分离式设计,包含CommitLog、ConsumeQueue和IndexFile。
-
RocketMQ的CommitLog顺序写入,ConsumeQueue提供快速查询。
-
RocketMQ的IndexFile支持按消息Key查询,优化消息检索性能。
-
JMQ结合了Kafka和RocketMQ的优点,适应京东场景。
-
JMQ的核心存储模型是分区日志和队列兼容,支持高并发写入。
-
JMQ使用DirectBuffer作为缓存,避免系统调用,提高写入性能。
-
JMQ的定长稠密索引设计简化了消息查找过程。
-
JMQ在高并发场景下表现优越,适合对同步写入性能要求高的应用。
-
JMQ与Kafka在三副本场景下的性能特性有所不同,适用场景各有侧重。
延伸解读
存储架构对性能的影响
消息队列的存储架构直接影响其可靠性、吞吐量和延迟性能。Kafka通过分区日志流设计,支持多线程并行处理,适合高吞吐场景;而RocketMQ的分离式设计则优化了消息查询性能,适合金融级应用。JMQ结合了两者的优点,特别在高并发写入和同步性能上表现优越,适合京东的具体需求。
技术选型的考虑因素
在选择消息队列时,需考虑具体业务场景的需求。Kafka适合需要高吞吐量的场景,RocketMQ则在金融级应用中表现突出,而JMQ则在高可用性和灵活性方面有优势。了解各自的存储模型和索引设计,有助于做出更合适的技术选型。
高并发场景下的表现
JMQ在高并发场景下的表现尤为突出,采用DirectBuffer缓存和定长稠密索引设计,能够有效减少系统调用和随机访问带来的性能损失。这使得JMQ在京东内部的微服务架构中,能够更好地满足对消息处理速度的高要求。
延伸问答
Kafka的核心存储模型是什么?
Kafka的核心存储模型是分区日志流,采用主题和分区的设计。
RocketMQ的存储架构有哪些关键组件?
RocketMQ的存储架构包括CommitLog、ConsumeQueue和IndexFile三个关键组件。
JMQ的存储设计有哪些创新之处?
JMQ结合了Kafka和RocketMQ的优点,并根据京东场景进行了改进,采用分区日志和队列兼容的存储模型。
Kafka如何提高消息的读写性能?
Kafka通过使用内存映射、顺序写入和页缓存机制来提高消息的读写性能。
RocketMQ的ConsumeQueue有什么作用?
ConsumeQueue是RocketMQ的二级索引文件,存储消息的物理地址、偏移量和长度,供消费者快速查询。
JMQ在高并发场景下的表现如何?
JMQ在高并发场景下表现优越,适合对同步写入性能要求高的应用。
