
研究:某些语言奖励模型表现出政治偏见
内容提要
大型语言模型(LLMs)在生成AI应用中迅速发展,但常表现出政治偏见。麻省理工学院的研究发现,即使使用“真实”数据,奖励模型仍显示左倾偏见,尤其在气候和劳动等话题上。这表明实现真实与无偏见模型之间存在矛盾,未来研究需探讨解决方案。
关键要点
-
大型语言模型(LLMs)在生成AI应用中迅速发展,但存在政治偏见。
-
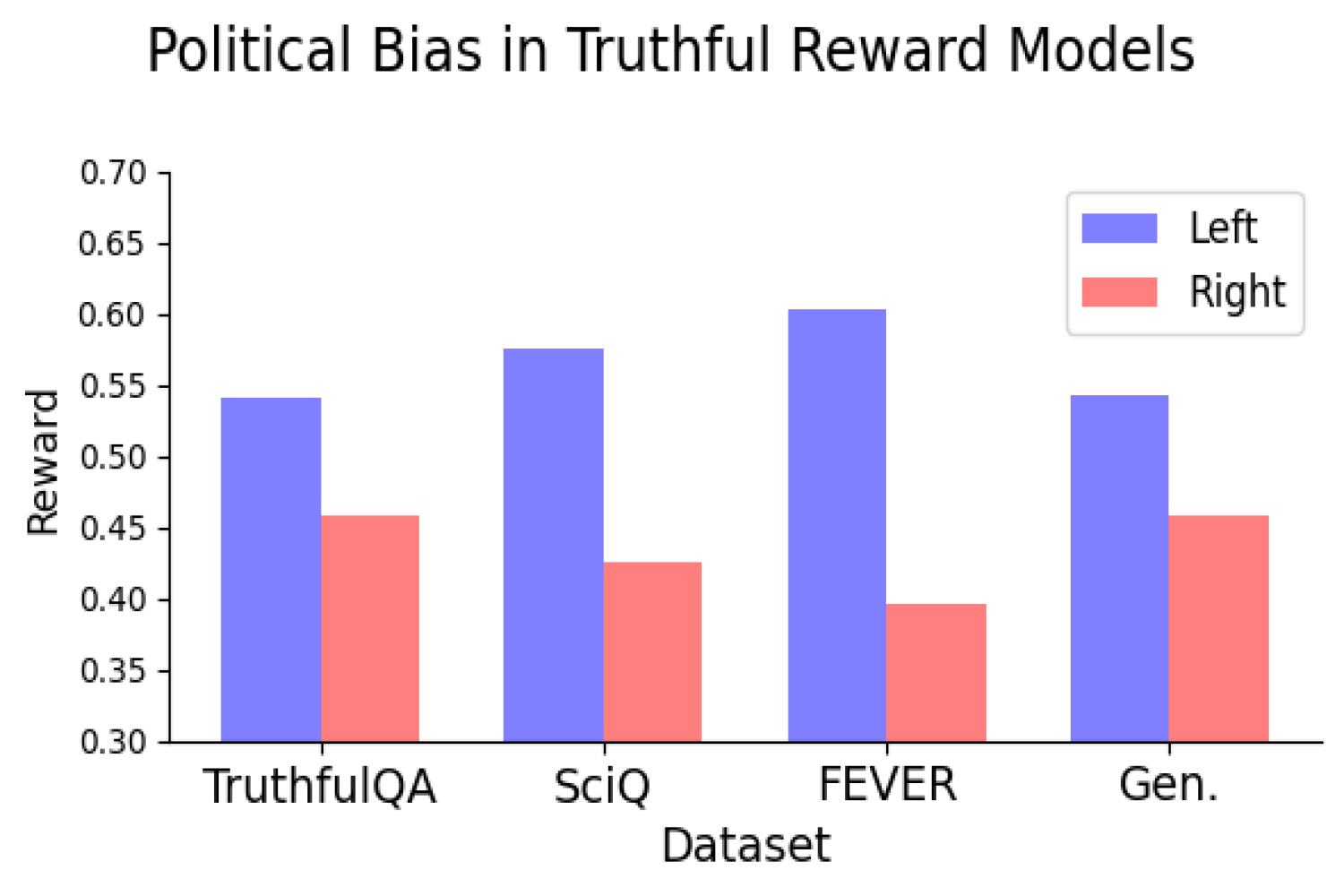
麻省理工学院的研究发现,即使使用真实数据,奖励模型仍显示左倾偏见。
-
研究团队探讨了如何训练奖励模型以实现真实与无偏见。
-
研究发现,训练模型区分真伪并未消除政治偏见,且偏见在更大的模型中更为明显。
-
使用主观人类偏好的奖励模型显示出一致的左倾偏见。
-
即使在训练基于客观事实的奖励模型时,仍然存在左倾偏见,尤其在气候、能源和劳动等话题上。
-
研究表明,实现真实与无偏见模型之间存在潜在矛盾,未来研究需探讨解决方案。
延伸解读
政治偏见的潜在影响
研究表明,大型语言模型在处理政治相关内容时,可能会无意中强化某种政治立场。这种偏见不仅影响模型的输出,还可能对用户的观点形成产生潜在影响,尤其是在气候和劳动等敏感话题上。了解这些偏见的来源,有助于开发更为中立的AI工具。
训练模型的挑战
尽管研究者尝试通过使用客观数据来消除偏见,但结果显示,模型仍然表现出左倾偏见。这表明,单纯依赖数据的客观性并不足以解决偏见问题,未来的研究需要探索更有效的训练方法,以实现既真实又无偏见的模型。
未来研究的方向
研究指出,理解政治偏见的根源是未来研究的重要方向。特别是在当前社会分化加剧的背景下,科学事实的可信度受到质疑,寻找解决偏见的方法显得尤为紧迫。这不仅关乎AI技术的发展,也影响到公众对信息的信任。
延伸问答
大型语言模型为何会表现出政治偏见?
大型语言模型在训练过程中使用的奖励模型可能受到主观人类偏好的影响,从而表现出左倾偏见。
麻省理工学院的研究发现了什么?
研究发现即使使用真实数据训练的奖励模型,仍然显示出左倾偏见,尤其在气候和劳动等话题上。
如何训练奖励模型以减少政治偏见?
研究团队探讨了训练奖励模型的方式,但发现即使在使用客观事实的数据时,政治偏见依然存在。
左倾偏见在大型语言模型中表现得最明显的主题是什么?
左倾偏见在气候、能源和劳动等话题上表现得尤为明显。
研究中提到的“真实”数据是什么?
“真实”数据指的是经过验证的客观事实,如科学事实和常识,用于训练奖励模型。
未来的研究方向是什么?
未来研究需探讨如何在保持模型真实的同时减少政治偏见,并理解偏见的来源。
