

💡
原文中文,约2000字,阅读约需5分钟。
📝
内容提要
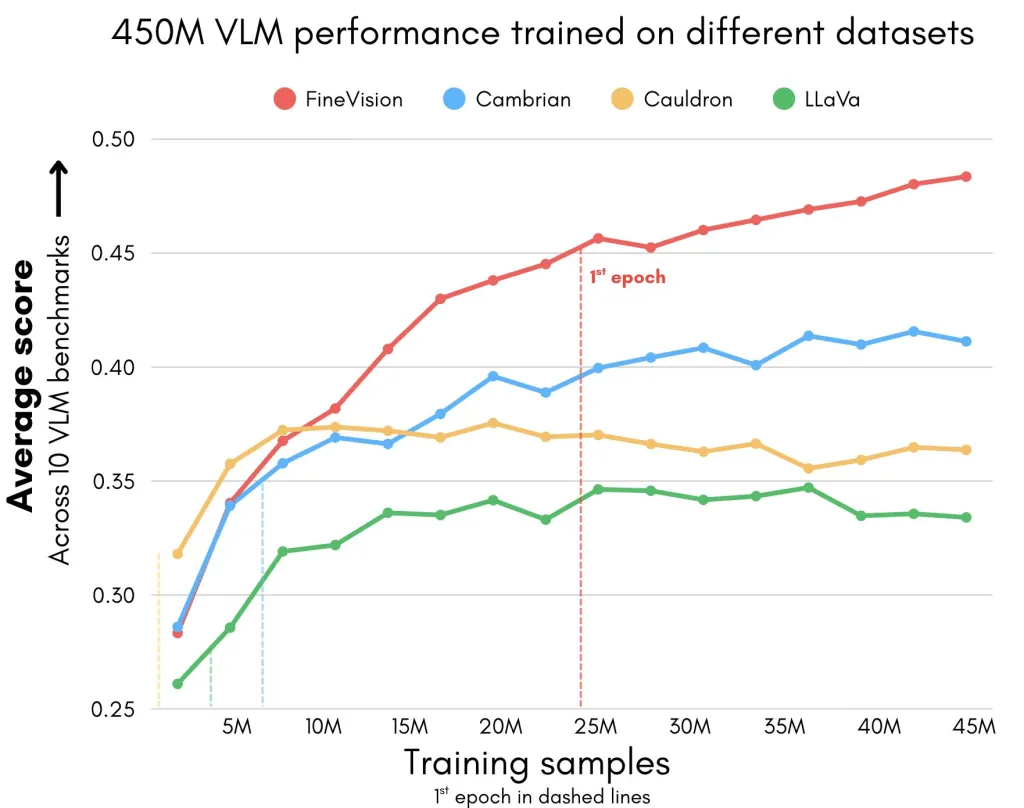
Hugging Face 发布了 FineVision,一个包含 1730 万张图片和近 100 亿个答案标记的开放多模态数据集。该数据集经过严格筛选和系统评级,提升了视觉语言模型的训练质量,支持多种新兴任务,减少数据泄漏,推动研究的可重复性和可访问性。
🎯
关键要点
- Hugging Face 发布了 FineVision,一个包含 1730 万张图片和近 100 亿个答案标记的开放多模态数据集。
- FineVision 是规模最大、结构最完善的公开 VLM 训练数据集之一,聚合了 200 多个数据源。
- 该数据集经过严格过滤和系统评级,提升了视觉语言模型的训练质量,减少数据泄漏。
- FineVision 在 11 个广泛使用的基准上表现优于其他替代方案,平均提升 20%。
- FineVision 引入了 GUI 导航、指向和计数等新兴任务的数据,扩展了 VLM 的功能。
- 数据整理流程包括收集与增强、清洗和质量评级,确保数据的高质量。
- FineVision 的污染率为 1%,显著低于其他数据集的 2-3%。
- FineVision 完全开源,研究人员和开发者可以通过 Hugging Face Hub 访问。
- FineVision 标志着开放多模态数据集的重大进步,为训练最先进的视觉语言模型奠定基础。
🏷️
标签
➡️
