
NVIDIA AI 发布 Nemotron Speech ASR:全新的开源实时转录模型
内容提要
NVIDIA发布了Nemotron语音识别模型,专为低延迟语音助手和实时字幕设计。该模型采用缓存感知的FastConformer编码器和RNNT解码器,支持16 kHz音频,提供多种输入块配置,词错误率在7.2%至7.8%之间,显著提升了并发性和稳定性,适用于实时语音应用。
关键要点
-
NVIDIA发布了Nemotron语音识别模型,专为低延迟语音助手和实时字幕设计。
-
Nemotron模型结合了缓存感知的FastConformer编码器和RNNT解码器,参数量为6亿。
-
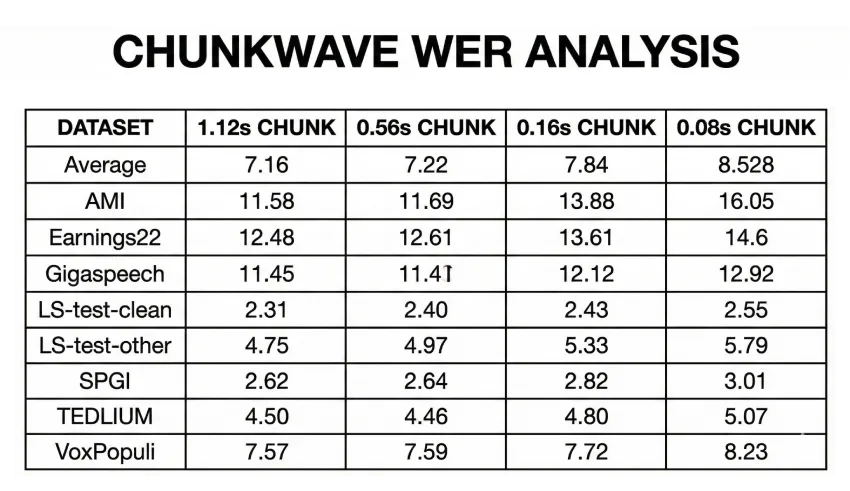
该模型支持16 kHz单声道音频,输入块至少为80毫秒,提供4种标准块配置。
-
模型通过可配置的上下文大小控制运行时延迟,支持不同的延迟与准确性权衡。
-
在Hugging Face OpenASR排行榜上,Nemotron的词错误率(WER)在7.2%至7.8%之间。
-
Nemotron的缓存感知流式处理消除了重叠窗口的重新计算,显著提升了并发性。
-
在NVIDIA H100 GPU上,Nemotron支持约560个并发流,延迟保持稳定。
-
模型主要基于NVIDIA Granary数据集的英语部分进行训练,结合了大量公共语音语料库。
-
Nemotron以NeMo检查点的形式发布,包含开放的权重和训练细节,便于团队微调和分析。
延伸解读
实时语音应用的优势
Nemotron模型的设计专注于低延迟和高并发性,使其非常适合实时语音助手和字幕生成等应用。通过缓存感知的流式处理,模型在高负载下能够保持稳定的延迟,这对于需要快速响应的场景尤为重要。开发者可以根据具体需求选择不同的输入块配置,以平衡延迟与准确性。
模型的灵活性与可调性
Nemotron提供了多种输入块配置,允许开发者在不重新训练模型的情况下,根据应用场景调整延迟和准确性。这种灵活性使得模型能够适应不同的使用需求,从快速响应的语音代理到以转录为中心的工作流程,均能找到合适的操作点。
并发性与性能提升
在现代NVIDIA GPU上,Nemotron模型的并发性显著提升,尤其是在H100 GPU上支持约560个并发流。这种性能提升使得模型在处理大量用户请求时,能够有效降低延迟,确保用户体验流畅。开发者在选择硬件时应考虑这一点,以最大化模型的性能。
延伸问答
Nemotron语音识别模型的主要用途是什么?
Nemotron语音识别模型主要用于低延迟语音助手和实时字幕生成。
Nemotron模型的词错误率是多少?
Nemotron模型的词错误率在7.2%至7.8%之间。
Nemotron模型如何提高并发性?
Nemotron模型通过缓存感知流式处理消除了重叠窗口的重新计算,从而显著提升了并发性。
Nemotron支持的音频输入格式是什么?
Nemotron支持16 kHz单声道音频。
如何选择Nemotron模型的输入块配置?
开发者可以根据应用需求选择输入块配置,如快速响应的语音代理可选择160毫秒,转录为中心的工作流程可选择560毫秒。
Nemotron模型的训练数据来源是什么?
Nemotron模型主要基于NVIDIA Granary数据集的英语部分进行训练,并结合了多个公共语音语料库。
