
LLM 究竟是如何工作的?
内容提要
本文介绍了大型语言模型(LLM)的工作原理,重点在于transformer架构的核心机制,包括分词、嵌入、位置编码和注意力机制。LLM通过将文本转换为整数序列,利用嵌入矩阵赋予这些整数含义,并通过注意力机制在token之间交换信息。模型的训练依赖于预测下一个token,架构的不同主要体现在训练权重和配置选择上。
关键要点
-
现代大型语言模型(LLM)主要基于transformer架构,理解其机制是掌握LLM的关键。
-
分词(tokenization)将文本转换为整数序列,模型通过分词器生成固定词汇表中的条目ID。
-
嵌入(embedding)将token ID映射到向量,赋予其语义含义,语义相似的token向量在空间中接近。
-
位置编码(positional encoding)为每个token提供位置信息,使模型能够理解token的顺序。
-
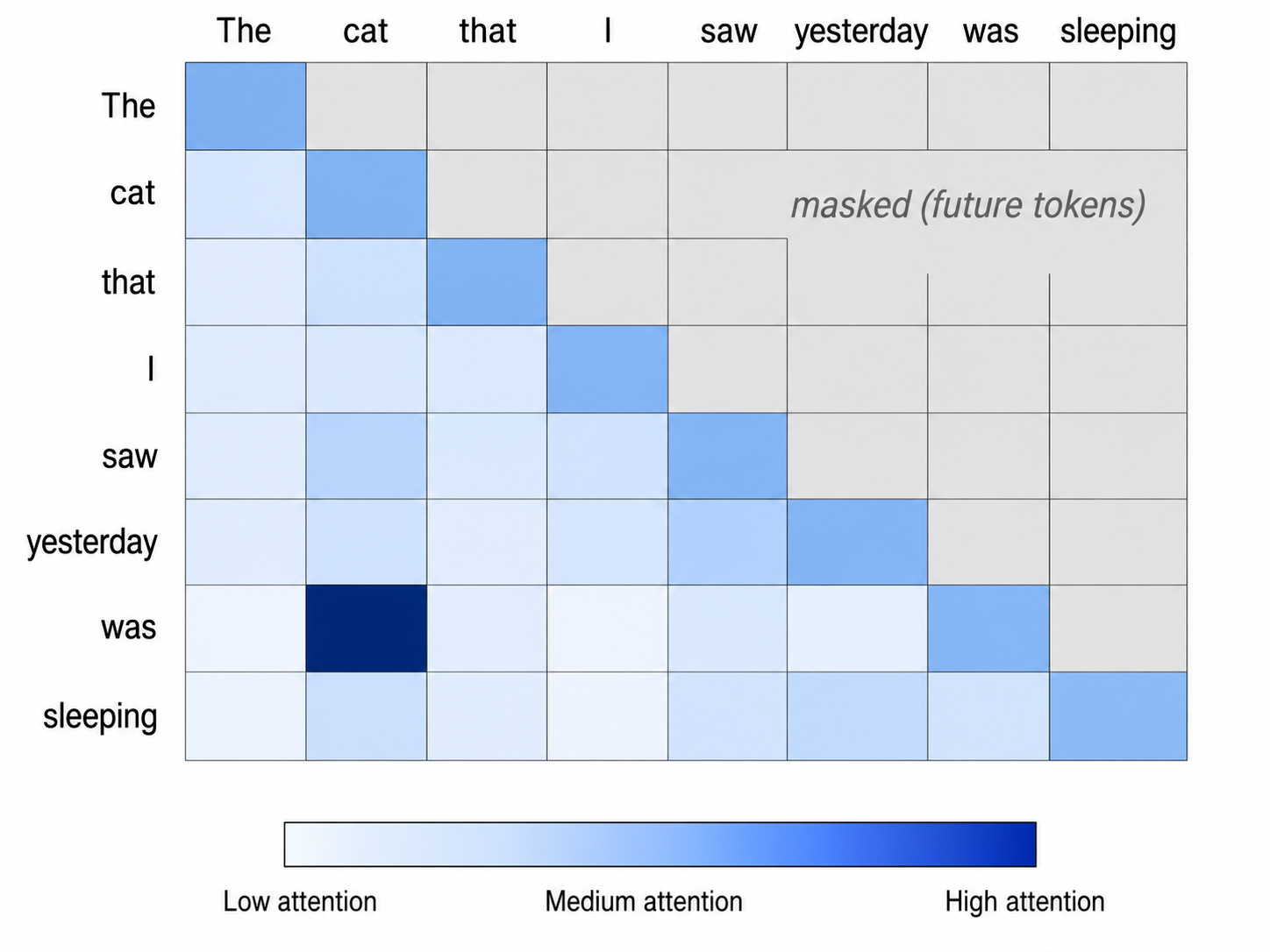
注意力机制(attention)允许每个token查看其他token并决定哪些重要,通过Query、Key和Value向量实现信息交换。
-
多头注意力(multi-head attention)通过并行运行多个注意力传递,捕捉语言中的多种关系。
-
前馈网络(feed-forward network)对每个token独立处理,增强模型的表达能力。
-
残差流与层归一化(residual stream and layer normalization)确保深层网络的稳定性和可训练性。
-
下一个token预测(next-token prediction)是LLM的核心任务,模型通过预测下一个token生成文本。
-
现代LLM之间的差异主要体现在训练权重、配置选择和后训练方法上。
延伸解读
理解Transformer架构的重要性
大型语言模型(LLM)大多基于Transformer架构,掌握其核心机制对于理解模型的工作原理至关重要。Transformer的设计使得模型能够有效处理序列数据,尤其是在自然语言处理任务中。了解分词、嵌入、位置编码和注意力机制的相互作用,可以帮助读者更深入地理解LLM的性能和局限性。
注意力机制的关键作用
注意力机制是LLM的核心,允许模型在处理每个token时考虑其他token的信息。这种机制通过Query、Key和Value向量的交互实现,使得模型能够捕捉到语言中的复杂关系。理解注意力机制的工作原理,有助于读者认识到模型在生成文本时如何选择和加权信息,从而影响最终输出的质量。
模型训练与后训练的区别
LLM的训练过程与后训练阶段存在显著差异。基础模型通过预测下一个token进行训练,而后训练则针对特定任务进行微调。这一过程使得模型能够更好地适应用户需求和安全性要求。了解这两者的区别,有助于读者理解模型在实际应用中的表现和适用性。
延伸问答
大型语言模型(LLM)是如何将文本转换为整数序列的?
LLM通过分词(tokenization)将文本转换为整数序列,分词器生成固定词汇表中的条目ID。
什么是嵌入矩阵,它在LLM中起什么作用?
嵌入矩阵是一个查找表,将token ID映射到向量,赋予每个token语义含义。
位置编码在LLM中有什么重要性?
位置编码为每个token提供位置信息,使模型能够理解token的顺序,从而影响句子的意义。
注意力机制是如何在LLM中工作的?
注意力机制允许每个token查看其他token并决定哪些重要,通过Query、Key和Value向量实现信息交换。
多头注意力有什么优势?
多头注意力通过并行运行多个注意力传递,能够捕捉语言中的多种关系,增强模型的表达能力。
LLM是如何进行下一个token预测的?
LLM通过对序列中的每个token生成一个向量,并使用最后一个token的向量预测下一个token,输出为每个可能token的概率分布。
