
NVIDIA AI 发布 Describe Anything 3B:用于细粒度图像和视频字幕的多模态 LLM
内容提要
NVIDIA推出的Describe Anything 3B(DAM-3B)模型,通过焦点提示和局部视觉主干,有效生成图像和视频的详细描述,克服了数据稀缺问题,表现优于其他模型,广泛应用于辅助功能和视频分析等领域。
关键要点
-
视觉语言模型在生成特定区域描述方面存在挑战,尤其是在视频数据中。
-
NVIDIA推出的Describe Anything 3B(DAM-3B)模型专为生成图像和视频中的本地化字幕而设计。
-
DAM-3B结合了焦点提示和局部视觉主干,采用门控交叉注意力机制以增强性能。
-
该模型能够处理静态图像和动态视频输入,并通过Hugging Face公开发布。
-
NVIDIA开发了DLC-SDP流程以克服数据稀缺问题,生成包含150万个局部化示例的训练语料库。
-
DAM-3B在七个基准测试中表现优异,超越了其他基线模型,平均准确率达到67.3%。
-
该模型广泛应用于辅助功能工具、机器人技术和视频内容分析等领域,为未来研究提供了强大基准。
延伸解读
多模态模型的优势
Describe Anything 3B(DAM-3B)模型通过结合焦点提示和局部视觉主干,能够有效处理图像和视频中的细节。这种多模态设计使得模型在生成本地化字幕时,不仅考虑了特定区域的细节,还保留了整体上下文,提升了描述的准确性和丰富性。
数据稀缺问题的解决
NVIDIA开发的DLC-SDP流程有效应对了训练数据稀缺的问题,通过半监督学习生成了150万个局部化示例。这一策略不仅提高了模型的训练质量,也为未来的研究提供了丰富的数据基础,推动了视觉语言模型的发展。
评估标准的创新
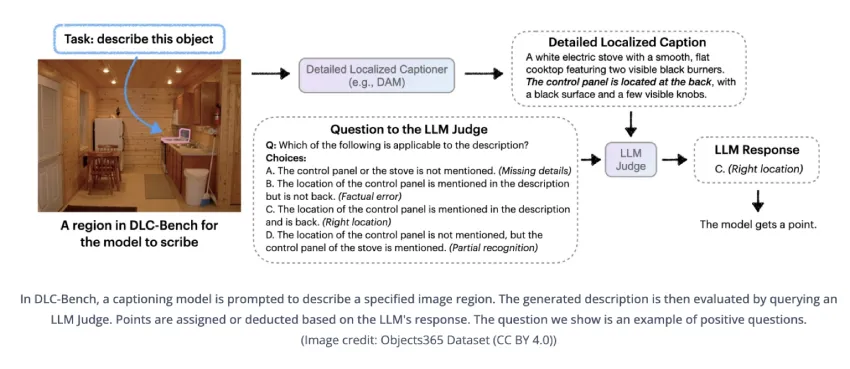
DAM-3B的评估采用了DLC-Bench,这一基于属性级别的评估方法,避免了与参考字幕的严格比较,提供了更为灵活和准确的描述质量评估。这种创新的评估方式为模型的性能提供了更全面的视角,值得其他研究者借鉴。
延伸问答
Describe Anything 3B模型的主要功能是什么?
Describe Anything 3B模型专为生成图像和视频中的本地化字幕而设计,能够提供详细的区域描述。
NVIDIA是如何解决数据稀缺问题的?
NVIDIA开发了DLC-SDP流程,这是一种半监督数据生成策略,整理出包含150万个局部化示例的训练语料库。
Describe Anything 3B在基准测试中的表现如何?
该模型在七个基准测试中表现优异,平均准确率达到67.3%,超越了其他基线模型。
Describe Anything 3B使用了哪些技术创新?
该模型结合了焦点提示和局部视觉主干,并采用门控交叉注意力机制以增强性能。
Describe Anything 3B的应用领域有哪些?
该模型广泛应用于辅助功能工具、机器人技术和视频内容分析等领域。
Describe Anything 3B如何处理视频数据中的动态变化?
DAM-3B-Video通过对帧内区域掩码进行编码并跨时间进行积分,能够为视频生成特定区域的描述,即使在存在遮挡或运动的情况下。
