
【前瞻技术布局】打破“沙漏“现象→提高生成式搜索/推荐的上限
内容提要
本文探讨了生成式搜索/推荐中的“沙漏”现象,指出中间层tokens过度集中导致数据稀疏和长尾分布。通过实验,提出移除第二层和自适应调整token分布的方案,有效提升模型性能,为未来优化奠定基础。
关键要点
-
本文探讨了生成式搜索/推荐中的“沙漏”现象,指出中间层tokens过度集中导致数据稀疏和长尾分布。
-
RQ-SID方法在电子商务领域表现出色,但面临“沙漏”现象的挑战。
-
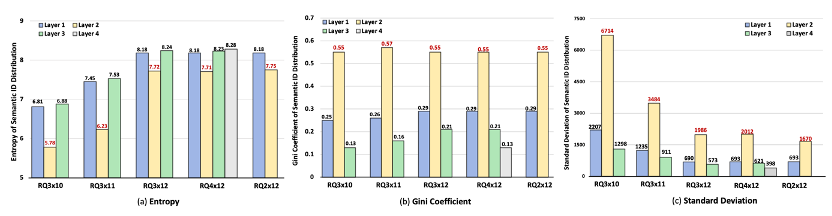
沙漏现象导致路径稀疏性和长尾分布,限制了生成式搜索/推荐的性能。
-
通过实验分析,发现第二层tokens的分布不均匀,影响了模型的表现。
-
提出两种解决方案:移除第二层tokens和自适应调整token分布。
-
实验结果表明,自适应token移除策略有效提升了模型性能。
-
未来规划包括优化SID的生产与表征方式,统一稀疏与密集表征,确保链路无损失实现一段式搜索。
延伸解读
沙漏现象的影响
沙漏现象在生成式搜索/推荐中造成了路径稀疏性和长尾分布,显著影响了模型的性能。尤其在电子商务领域,头部标记的表现优于尾部标记,导致推荐系统的效果不均衡。理解这一现象有助于优化推荐算法,提升用户体验。
解决方案的实用性
文章提出的两种解决方案,移除第二层tokens和自适应调整token分布,均有效缓解了沙漏现象的影响。这些方法在实际应用中具有较高的可操作性,尤其适合需要快速迭代和优化的电商平台。
未来优化方向
未来的研究方向包括优化SID的生成与表征方式,统一稀疏与密集表征。这将有助于提升生成式搜索的准确性和效率,特别是在处理复杂的用户行为数据时,确保推荐系统的灵活性和适应性。
延伸问答
什么是生成式搜索/推荐中的“沙漏”现象?
“沙漏”现象是指中间层tokens过度集中,导致数据稀疏和长尾分布,从而限制了生成式搜索/推荐的性能。
RQ-SID方法在电子商务中面临哪些挑战?
RQ-SID方法在电子商务中面临的挑战主要是“沙漏”现象,这导致路径稀疏性和长尾分布,限制了模型的表现。
如何解决生成式搜索中的沙漏现象?
解决沙漏现象的方法包括移除第二层tokens和自适应调整token分布,这两种方法都能有效提升模型性能。
沙漏现象对模型性能有什么影响?
沙漏现象导致模型在处理头部标记时性能提升显著,而在处理尾部标记时性能明显下降,影响了整体效果。
实验中如何验证沙漏现象的存在?
通过对第二层标记分布的统计分析和可视化实验,发现第二层标记表现出低熵、高基尼系数和大标准差,支持了沙漏现象的存在。
未来对生成式搜索/推荐的优化方向是什么?
未来的优化方向包括优化SID的生产与表征方式,统一稀疏与密集表征,以及确保链路无损失实现一段式搜索。
