
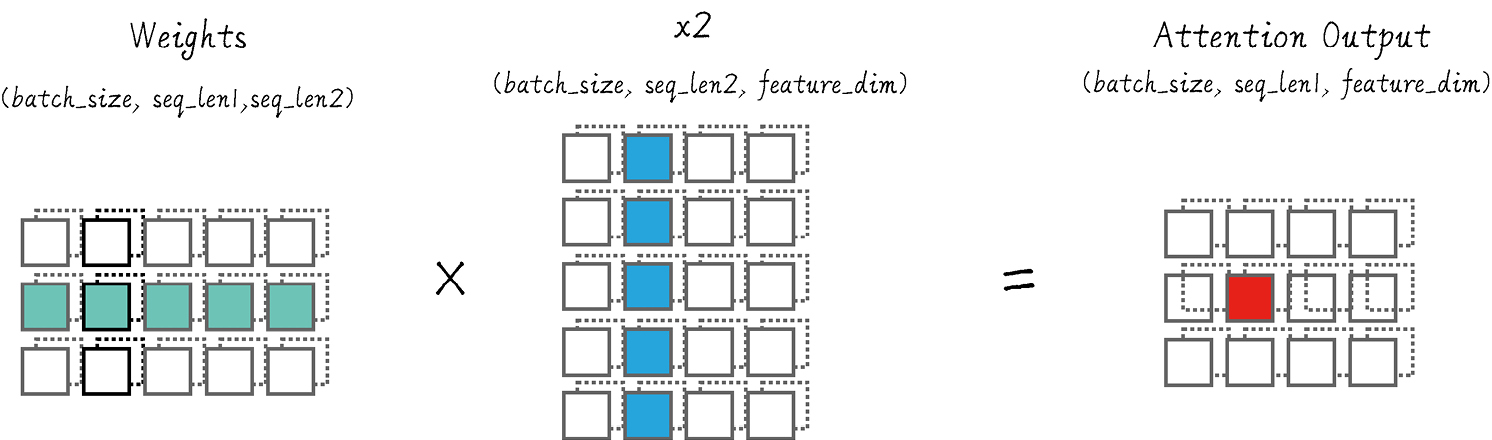
《GPT 图解》笔记:Seq2Seq及点积注意力
Ying’s Blog
·

AI 潮来,翻译何为
少数派
·


从零开始构建神经机器翻译 – PyTorch重现7篇重要论文
freeCodeCamp.org
·

绝对初学者的5个有趣的自然语言处理项目
KDnuggets
·

JetBrains Academy 插件迎来 AI 驱动的学习功能
The JetBrains Blog
·

迈向机器翻译:来自人类翻译研究的启示
Apple Machine Learning Research
·

在线教程丨ACL机器翻译大赛30个语种摘冠,腾讯Hunyuan-MT-7B支持33种语言翻译
HyperAI超神经
·
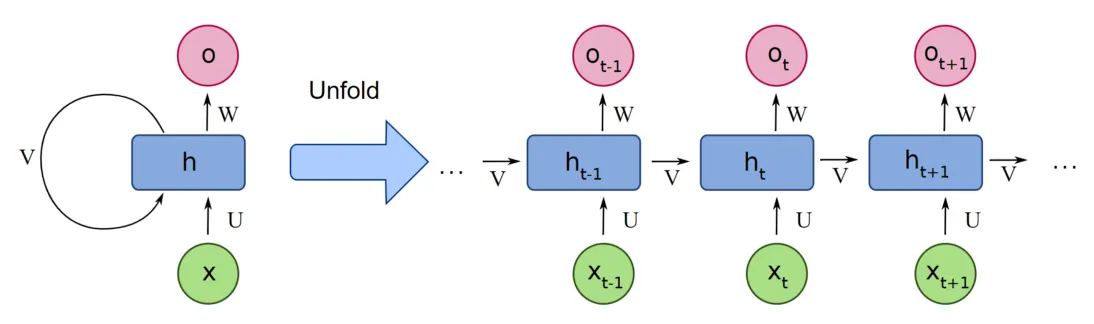
深入理解大模型 1:Transformer,大模型的基石
木鸟杂记
·

AI 驱动的全球通信语言解决方案的进步
实时互动网
·
最优语料感知训练用于神经机器翻译
Apple Machine Learning Research
·
通过像素级回退克服词汇限制
Apple Machine Learning Research
·
超越文本压缩:跨规模评估分词器
Apple Machine Learning Research
·
