神雲科技在WAIC展出全方位服务器矩阵与超高密度整柜液冷解决方案
全球TMT-美通国际
·
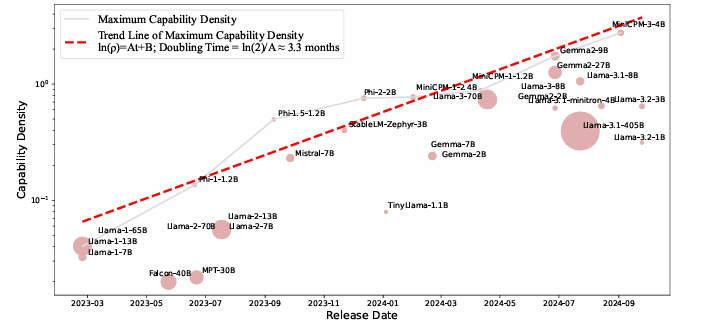
有人靠CPU把AI算力密度卷到了新高度
量子位
·


罗杰斯定理在筛选理论中的应用
What's new by TerryTao
·

DBSCAN:识别任意形状的聚类
DEV Community
·