
DuoCore-WB——视觉驱动的全身行走-操作:让轮式人形自主开门后给会议室的客户递杯水
结构之法 算法之道
·

AI 论文周报丨递归推理方法/轻量级解码器架构/深度卷积神经网络架构……多领域前沿动态一览
HyperAI超神经
·
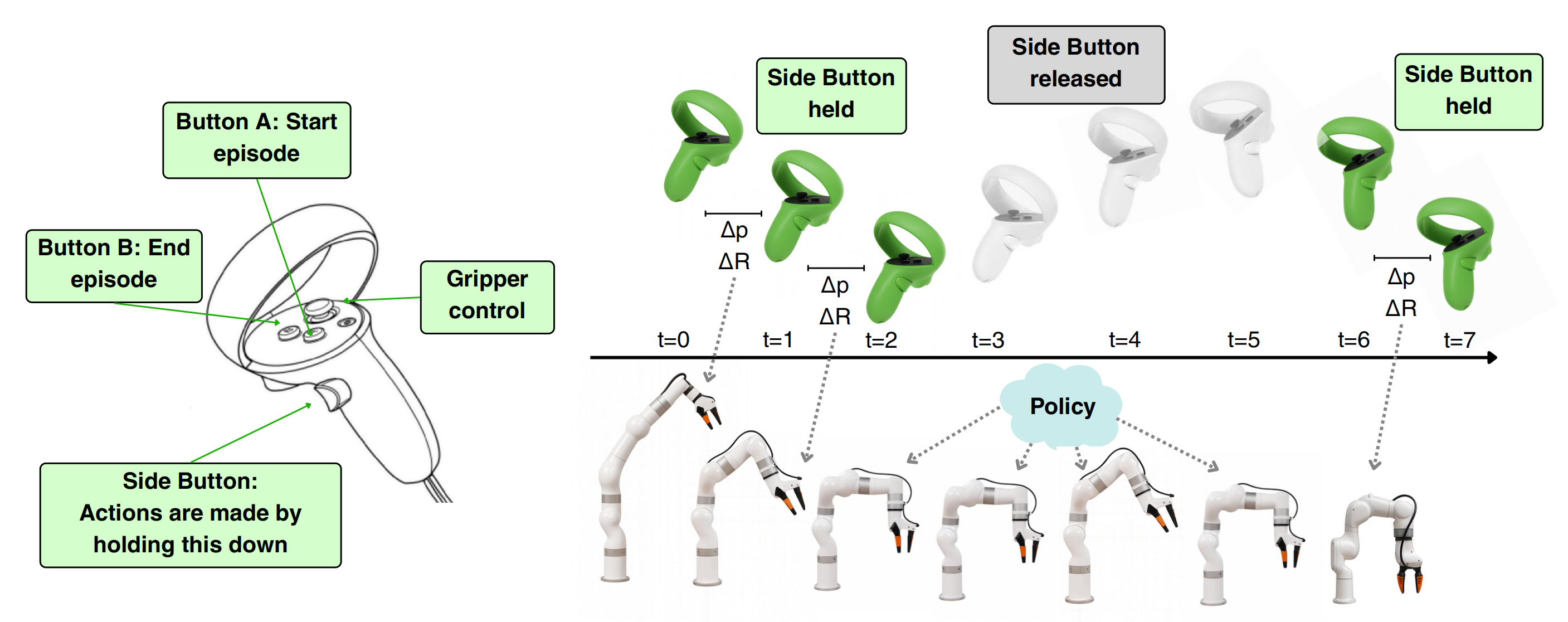

EgoDex:从大规模自我中心视频中学习灵巧操作
Apple Machine Learning Research
·
通过分解缩放曲线指导数据收集
BriefGPT - AI 论文速递
·
