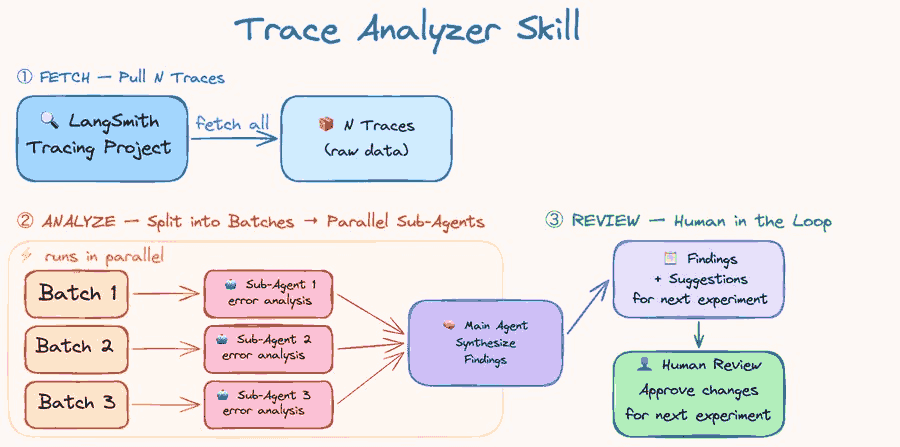
Langchain团队通过开源评估架构,优化深度代理的能力评估,涵盖文件操作、工具选择和记忆管理等方面。采用标签分组和自我验证机制,确保代理在多轮对话中有效处理信息,评估结果追踪至LangSmith,以便分析和改进。
Kaggle Game Arena是一个新的公开AI基准测试平台,允许AI模型在战略游戏中竞争,旨在提供动态、可验证的能力评估。游戏能够清晰反映模型的战略推理和适应能力。首场国际象棋展览赛将于8月5日举行,未来将增加更多挑战和比赛。
本研究提出了LLM-KG-Bench 3.0框架,旨在评估大语言模型在知识图谱应用中的能力,提升评估的灵活性,并生成包含30多种模型的数据集。
本研究提出了一种新的度量标准——50%任务完成时间标准,以评估人工智能在现实世界中的能力。研究表明,当前AI模型完成任务的时间约为50分钟,自2019年以来,其能力每七个月翻倍,未来五年可能使AI自动化许多人类需一个月完成的任务。
面试中评估候选人能力困难,传统问题难以真实反映其工作能力。作者建议使用“告诉我如何去你最喜欢的餐厅”这一问题,以揭示候选人的思维方式和应对能力,促进深入对话,帮助面试官更好地评估候选人。
国内外公司面试风格差异明显。国内公司主要考察技术知识,准备相对简单;而国外公司则综合评估表达、沟通和思维能力,难度较大,需要深入研究和实践。
本研究分析了人工智能基准评估方法的不足,涵盖约100项研究,揭示了量化基准在能力、安全和风险评估中的局限性。强调基准设计中的细节问题及社会技术相关的缺陷,呼吁提升AI基准的问责性和相关性,以应对现实世界的复杂性。
本研究提出了新基准数据集VQA-Levels,系统评估视觉问答(VQA)系统的能力。结果表明,现有系统在简单问题上表现良好,但在复杂问题上的成功率较低,为未来研究提供了参考。
本研究探讨了如何准确评估人工智能系统的能力,特别是潜在能力的引出。研究表明,通过引入新模型训练方法,结合多种技术,能够显著提高能力引出效果,微调是提升评估可靠性的首选。
本研究推出的说与提高语料库2025,旨在解决L2学习者英语口语数据不足的问题。该语料库提供带整体评分和语言错误注释的开放口语测试数据,支持口语能力评估和语法错误反馈,促进相关技术研究。
本研究提出了一种基于扩散模型的认知状态迁移框架(DCSR),旨在解决计算机自适应测试中的冷启动问题。该方法通过建立领域间的认知状态转移桥梁,显著改善了对考生能力的初步理解,实验结果表明其性能优于现有方法。
获得技术职位不仅需要编程能力,还需在面试中展示实际应用技能。行为面试评估沟通、适应、解决问题和压力处理能力,需用STAR方法准备。技术面试考察算法和系统设计等硬技能。两者结合全面评估能力,准备时需兼顾技术和行为问题。
研究探讨大型语言模型在真实任务中多种能力的交叉表现,提出CrossEval基准,发现表现受最弱能力限制,强调提升弱项的重要性。综述LLMs的评估方法,提出综合评估平台,包括知识、能力、对齐和安全评估。通过跨语言反馈扩展多语言能力,支持100种语言,揭示弱LLM在对齐方面的潜力,为可持续对齐策略提供新视角。
本研究提出了一种基于概率和重建的能力评估方法(PaRCE),旨在提高无人地面车辆在复杂地形中的导航安全性。PaRCE有效预测分类结果,减少与不熟悉障碍物的碰撞,提升导航效率。
本文总结了多模态大型语言模型(MLLM)的最新进展,重点评估其在数学推理和视觉背景下的能力。研究提出了MathVista和Multi等基准测试,以评估模型在复杂任务中的表现。结果表明,现有模型在数学推理方面与人类存在差距,强调了进一步发展的必要性。同时,通过新方法生成的数学问题数据集和评估策略,推动了MLLM在视觉数学问题解决能力的提升。
本文介绍了ElitePLM对预训练语言模型(PLMs)的实证研究,评估其在记忆、理解、推理和组合等四个维度的能力。实验结果表明,PLMs在多项能力测试中表现优异,且在下游任务中微调对数据敏感。研究探讨了大型语言模型在认知模型中的应用潜力,强调其与儿童语言习得的联系及在决策制定中的表现。
人工通用智能(AGI)旨在实现类似人类的适应能力和自主学习。研究提出了AGI模型及其能力分类框架,强调能力评估和阶段定义。文章探讨了AGI在教育中的应用及伦理问题,强调跨学科合作的重要性,并分析了AGI对艺术与人文学科的影响,提出多方合作以确保AI的负责任发展。
OpenAI成立于2015年,作为非营利组织,致力于确保通用人工智能造福全人类,重点关注AI能力评估、红队测试和合成媒体来源问题。
该文介绍了一种通过实验数据推断机器学习模型认知特征的方法,并使用 PyMC 推断不同认知特征的代理在动物人工智能奥林匹克的实际参赛选手和合成代理的能力,展示了基于能力的评估的潜力。
面试题反映了面试官对候选人能力的评估。通过兴趣和技术领域的问题,面试官可以了解候选人的思维方式和深入程度。面试重视思考过程和逻辑推理能力,同时有效的沟通和问题分析能力也至关重要。
完成下面两步后,将自动完成登录并继续当前操作。