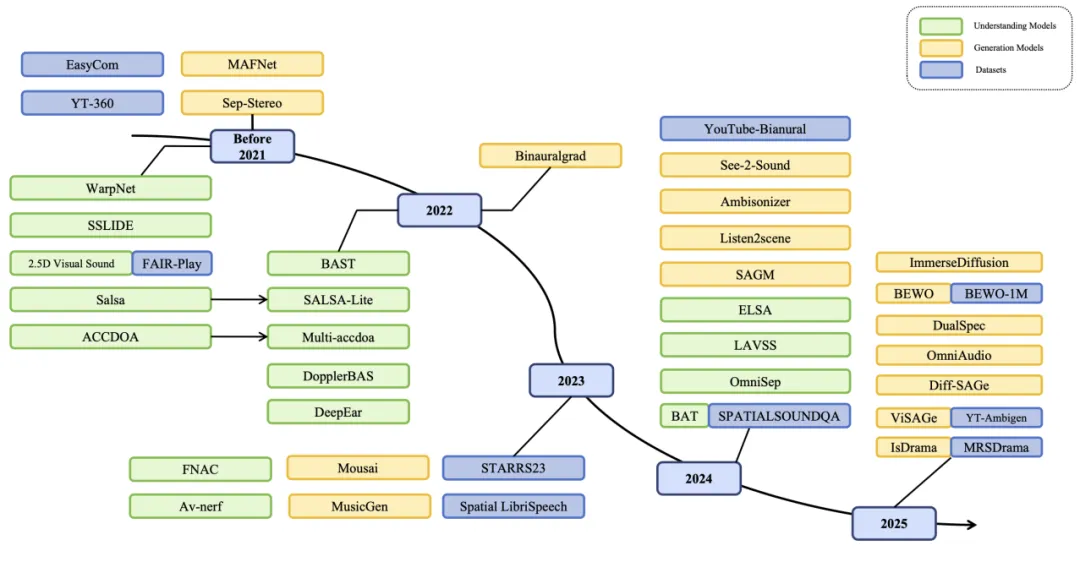
近年来,空间音频技术迅速发展,研究重点已转向多模态生成与语义推理。浙江大学的学者系统梳理了空间音频的表示、理解、生成任务及评测标准,撰写了综述文章ASAudio,填补了该领域的文献空白。
本研究提出了一种基于范畴逻辑的智能代理设计方法,旨在解决传统逻辑在对象推理中的不足。通过约翰斯通的序列演绎法,开发了前向链和标准形式算法,适用于不支持经典逻辑的语义推理。
本文提出了一种上下文敏感的语义推理系统,通过非结构化文本构建动态知识图谱,实现类比推理。该系统利用TF-IDF提取重要词汇,借助预训练语言模型推断关系三元组,并在图中形成有向边,支持多语言输入,能高效处理复杂查询,并逐步更新知识以应对矛盾和知识演变。
2025年2月,AI研究团队发布了NoLiMA论文,提出了评估大语言模型处理长文本的新基准。研究揭示了现有模型在长上下文中依赖表面匹配的局限性,并强调了语义推理能力的快速下降。此外,研究还探讨了嵌入模型在不同上下文长度下的表现,发现即使使用查询扩展,性能仍显著下降。
本研究探讨了低各向同性对语义推理任务的负面影响,提出了一种改进的ZCA白化技术,以提高嵌入的各向同性水平。研究结果表明,软ZCA白化能够提升预训练代码语言模型的性能。
该研究提出了一种基于知识图谱的语义推理框架,结合KagNet模型和ConceptNet资源,提升了CommonsenseQA数据集的表现。通过图卷积网络和注意机制,显著提高了常识问答的准确性,并探讨了多种知识源的集成及子图检索器的应用,解决了大型语言模型的推理问题。
RT-2模型将预训练的视觉-语言大模型集成到机器人的低级控制中,以提高泛化能力和语义推理。RT-2具备多模态推理能力,优于基线模型。然而,由于数据集限制,RT-2无法学习新的行为。
本文介绍了一种开放词汇的3D场景图(OVSG),用于将实体与自由文本查询关联,支持上下文感知的实体定位。实验表明,OVSG在机器人导航和操作中表现优越,能够处理复杂的空间和语义推理任务,显著提高了3D场景图的生成质量。
通过在互联网数据上训练视觉语言模型,将其融入机器人控制,提高泛化能力和语义推理。RT-2在训练中获得新能力,包括对新对象的泛化、解释不在训练数据中的命令和初步推理用户指令。RT-2还可进行多阶段的语义推理。
通过在互联网数据上训练视觉语言模型,将其融入机器人控制,提高泛化能力和语义推理。RT-2在训练中获得新能力,包括泛化能力、解释新命令和初步推理。RT-2还可以进行多阶段的语义推理。
通过在互联网数据上训练视觉语言模型,将其融入机器人控制中,提高泛化能力和语义推理。实验证明该方法可得到性能优越的机器人策略,使机器人获得新兴能力,如泛化能力、解释新命令的能力和初步推理能力。通过思维链式推理,机器人可进行多阶段的语义推理。
该文介绍了一种名为视觉语言行动模型(VLA)的机器人控制模型,通过在互联网规模的数据上训练视觉语言模型,将其直接融入端到端的机器人控制中,提高泛化能力和实现新兴的语义推理。该模型可以对新对象进行泛化,解释不在机器人训练数据中的命令,并对用户指令做出初步推理。同时,该模型还可以进行多阶段的语义推理。
本文介绍了大型语言模型以类似知识库的方式组织概念,提供了推理语义和世界知识的高质量表征。更大更好的模型表现出更符合人类的概念组织,涵盖了四个系列的语言模型和三个知识图谱嵌入。
该文章介绍了一种新型的多任务学习系统,将外观和运动线索相结合,以更好地对环境进行语义推理。该系统使用联合车辆检测和运动分割的统一架构,并在KITTI数据集上评估了该方法。结果表明,在运动检测任务上的性能优于其他利用运动线索方法21.5%,在通用物体分割任务上表现与现有的无监督方法相当。此外,运动分割与车辆检测的联合训练有益于运动分割。
该文介绍了一种名为语义推理(SINF)的新框架,通过利用潜在表示中的内在冗余来减少计算负担,可以识别物体属于的语义簇并执行与该语义簇相关的子图进行推理。在基准测试中,SINF 可以减少 VGG19、VGG16 和 ResNet50 的推理时间,同时只损失少量精度。
该文介绍了一种基于仿真和语义推理的机器人拾取和放置任务方法,能够输出放置任务的可能候选位置的概率分布,考虑到任务的稳定性和合理性。在仿真和真实环境中进行了评估,证明了该方法提高了放置任务的可信度和合理性。
该研究提出了一种简单易解释的推理模型,用于生成全局场景的主要对象和语义概念的可视化表示。该模型使用图卷积网络进行关联和推理,并使用门和记忆机制进行全局语义推理。实验证明该方法在MS-COCO和Flickr30K数据集上取得了相对于最佳方法分别为6.8%和4.8%的图像检索和字幕检索的新的最佳效果,Flickr30K数据集上分别提高了12.6%和5.8%的图像检索和字幕检索。
完成下面两步后,将自动完成登录并继续当前操作。