Databricks推出的TAO方法能够在无标注数据的情况下微调大型语言模型(LLMs),其性能超越传统方法。TAO通过测试时计算和强化学习提升模型质量,降低企业成本。实验表明,TAO显著提升了Llama模型在企业任务中的表现,达到了商业模型水平。
AIxiv专栏促进学术交流,报道超过2000篇内容。李学龙教授团队提出COPO方法,增强大型语言模型的探索能力,克服对齐框架的局限性,提高模型性能与安全性。该研究成果已被ICLR 2025录用,验证了在线学习的有效性。
港大黄超教授团队提出的GraphAgent框架,通过多智能体协作,融合图数据与文本信息,显著提升预测与生成任务的性能。在8B参数下,该框架优于70B大模型,尤其在论文评审中有效预测录取可能性,展现出良好的零样本学习和跨域泛化能力。
Meta 发布了唯一开源的 Llama 3.3 模型 Llama-3.3-70B-Instruct,其性能可与 405B 模型媲美。该系列的最后一款模型,期待 Llama 4 的推出。hyper.ai 提供一键部署及优质数据集和教程,支持 AI 研究与应用。
Meta 发布了唯一开源模型 Llama 3.3 的 Llama-3.3-70B-Instruct,性能可与 405B 模型媲美。该系列的最后一款模型,未来将推出 Llama 4。hyper.ai 提供一键部署及优质数据集和教程,提升用户体验与研究。
研究表明,通过延长思考时间,小模型在性能上可以超越大模型,尤其在资源受限的情况下。HuggingFace探索了多种搜索策略,发现集束搜索和多样性验证器树搜索(DVTS)显著提高了小模型在复杂数学问题上的准确性。
Meta发布的Llama 3.3以70B参数实现405B性能,成本显著降低。谷歌的Gemini 1206更新后重回榜首,马斯克的Grok 3即将发布,市场竞争激烈。
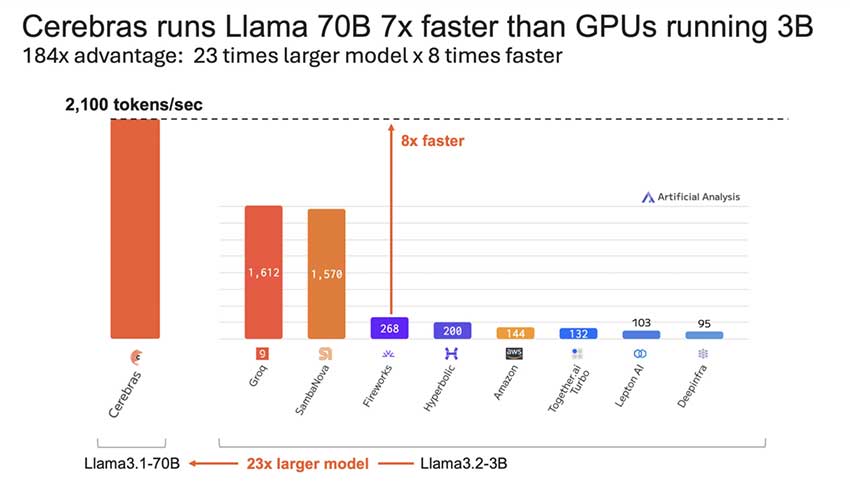
Cerebras Systems 实现了推理速度提升三倍,使用 Llama 3.1-70B 模型每秒处理 2,100 个 Token,速度比最快 GPU 快 16 倍。通过优化算法和异步计算,显著提升了 AI 在医疗和实时通信等领域的应用效率。
Imbue公司成功训练了一个70B参数的语言模型,并分享了数据集创建、评估和基础设施设置的经验。他们开发了超参数优化器CARBS,帮助研究者在小规模实验中找到最佳超参数,以便扩展到大规模模型。通过大量实验,Imbue团队优化了模型性能,确保训练过程的稳定性。
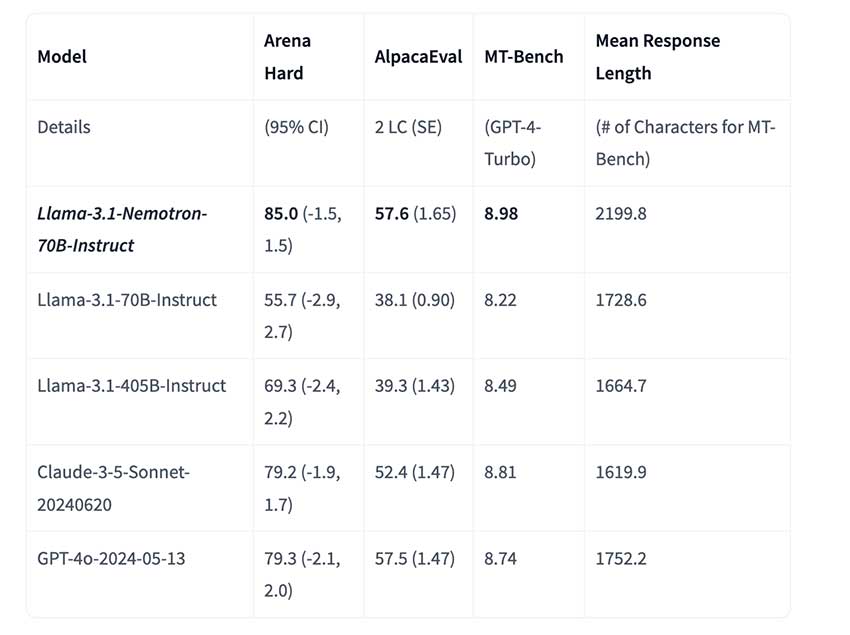
英伟达开源了大模型Llama-3.1-Nemotron-70B-Instruct,其性能仅次于OpenAI最新模型,并在多个基准测试中表现优异。英伟达还开源了训练数据集HelpSteer2和奖励模型。该模型使用RLHF技术训练,需特定硬件部署。
Nvidia 推出的 Nemotron 70B 是 Llama 3.1 系列的一部分,拥有 700 亿参数,提升了生成式 AI 的稳健性、准确性和效率。该模型支持微调,适用于金融和医疗领域,推理速度快,能耗低,性能超越 GPT-4,在语言理解任务中表现出色。
该项目使用Next.js和React开发AI聊天机器人,集成NVIDIA Llama 3.1 Nemotron-70B模型。前端采用Tailwind CSS,支持实时聊天和自定义应用,具备暗/明模式切换、响应式设计和安全API。用户可个性化界面。项目开源,欢迎贡献。
Imbue团队成功训练了一个70亿参数的大模型,分享了集群配置、GPU通信、故障诊断和健康检查等经验,强调了自动化和稳定性在高效模型训练中的重要性。
本研究评估了开源聊天机器人的性能,提出了LLaMA和Alpaca模型,以提升中文语义理解能力。构建了Aurora模型,验证其在中文对话中的有效性,并提出ChatFlow模型,实现高性能训练。研究还探讨了持续预训练和关键混合比的优化策略,提升了模型在特定领域的表现。
Imbue公司在6月预训练了一个70B参数的模型,并在多个基准测试上进行了微调。微调后的模型在多个数据集上表现优于GPT-4o zero-shot模型。他们发布了工具和数据集,帮助其他团队进行模型训练和评估。他们清洗了11个公共数据集,并创建了一个用于代码理解的数据集。开源和闭源模型在高质量问题下的准确率接近100%。他们还讨论了数据集创建和清洗过程,并与其他前沿模型进行了比较。
本文介绍了使用Meta的Llama 3.1 70B构建智能面试模拟器的过程,使用Streamlit作为基础,通过Tune Studio的API调用实现模型部署和推理。文章提供了生成回答和评估的代码示例,并介绍了使用FPDF生成PDF报告的方法。面试模拟器展示了Llama 3.1 70B的潜力。
本文探讨了在Amazon P5(H100 GPU)上部署Llama-3-70B模型的FP8精度推理方案,涵盖性能评估、TensorRT-LLM优化建议及最佳实践。Llama-3模型采用新Tokenizer和高效的分组查询注意力,提升了多语种处理能力。FP8格式在动态范围和显存占用上优于INT8和FP16,适合大型语言模型的量化。通过Triton和LMI容器,用户可快速搭建高性能推理服务,并建议根据实际业务场景进行压测和优化。
Meta在Amazon Bedrock上线Llama 3.1模型,支持128K上下文长度,容量是Llama 3模型的16倍。Llama 3.1在行业基准测试中表现出色,提供多语言对话用例推理效率。
本教程介绍了Groq LPU推理引擎以及如何在Jan AI和VSCode中使用它来生成超快速的响应。通过安装Jan AI和创建Groq Cloud API,可以在本地使用Groq LPU技术,使LLMs变得超快,并在实时AI应用中提供更好的性能。在Jan AI和VSCode中集成Groq,可以生成代码、重构代码、文档化和生成测试单元。这个教程还提供了使用Groq的步骤和注意事项。
Meta宣布开源Llama 3,号称最好的开源大模型,采用先进指令调优技术,安全性更好。Llama 3在真实世界场景中性能优于其他模型,可解决征求建议、分类、编程、翻译等问题。HyperAI超神经提供了部署Llama 3的教程,Meta还在训练超过400B参数的新版本模型。
完成下面两步后,将自动完成登录并继续当前操作。