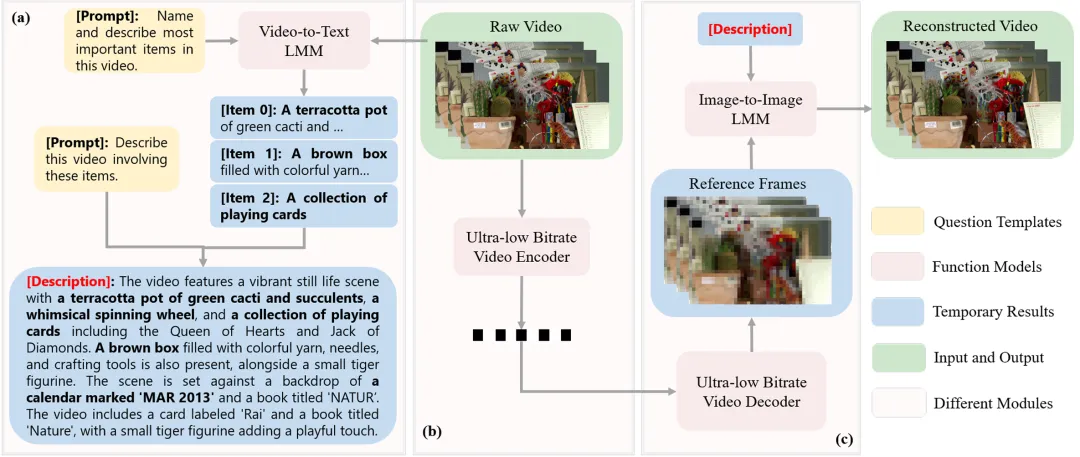
近年来,超低码率视频压缩面临性能挑战,导致视频质量下降。为此,提出了一种基于多模态大模型的语义压缩方法LMM-VSC,通过提取语义信息和生成参考视频,显著提高了超低码率下的视频质量。实验表明,该方法在保持感知质量的同时,降低了68.4%的比特率,具有较高的实际应用价值。
当前顶尖的LMM在ZeroBench基准测试中表现不佳,20多个模型均得零分。ZeroBench包含100个挑战性问题,考察模型的视觉理解和推理能力,揭示了现有基准的不足。
Meta AI与斯坦福大学联合开发的Apollo视频多模态模型,旨在提升视频理解能力。Apollo通过优化设计和双视觉编码器,支持处理最长一小时的视频,性能超越多种大型模型,为视频问答和内容分析提供有效解决方案。
该研究解决了在低资源环境下有效识别有害表情包的问题,提出了一种基于代理的框架,利用少量标注样本的内外分析。通过引入大型多模态模型(LMM)的推理能力,研究展示了该方法在检测有害表情包方面的优越性能,具有重要的实用价值。
本文探讨了无监督微调CLIP模型及其在视觉语言模型中的应用,提出了通用熵优化(UEO)方法,显著提升了模型的泛化能力和未知类别样本检测。研究还介绍了AutoCLIP、MetaCLIP和VeCLIP等新方法,改善了数据质量和模型性能,尤其在零样本分类任务中表现优异。
本文探讨了医学图像分割的多种技术,包括模型预训练、数据处理和增强,强调这些技巧对模型性能的影响。研究提出了SAT模型,通过文本提示实现医学图像分割,并结合多模态数据和语言模型提升分割效果。此外,提出了新的医学图像引导分割任务(MIRS)和框架MOSMOS,以提高病灶识别的准确性和效率。
本文讨论了将大模型视为操作系统和廉价诱导需求的概念。大模型可以像操作系统一样使用,核心是LMM,内存是上下文窗口。廉价诱导需求悖论指出,当某物变得更高效时,人们会消费更多。文章还介绍了一些新功能和开源软件。最后,作者分享了维护副项目的经历和教训。
GPT-4V是一种结合了文本和图像处理能力的AI模型,可用于图像描述和创意设计等应用。然而,它在准确性和幻觉方面仍存在局限性。它适用于自动图像筛选和创意工作,但不适用于精确的文本相关任务或复杂的图像。GPT-4V能够识别多个图像,并在医学成像和皮肤疾病诊断等各种场景中进行了测试。由于隐私问题,它不适用于人脸识别。
本文探讨了多模态大型语言模型(如MiniGPT-4和Emotion-LLaMA)在情感识别和图像分类中的应用。通过整合音频、视觉和文本输入,显著提升了情感识别能力,并在多个数据集上取得了优异成绩。此外,RAEmoLLM框架在虚假信息检测中表现出色,提升了检测准确性。
本文提出了一种新方法,通过多模态模型密集连接视觉实体,利用无类别分割生成实体级分割,并通过特征融合提高细粒度预测效率。研究表明,该方法在全景叙事连接、指称表达分割和全景分割任务中表现优越。同时,探讨了大型语言模型在图像生成中的应用,提出高效训练流程以提升生成质量,并分析了多模态模型的能力与特点。
本文介绍了FakeBench,这是首个透明的虚假图像检测基准,包含多样化的虚假和真实图像数据集。研究表明,现有大型多模态模型在图像虚假检测方面的能力有限。此外,提出了MLLM-Bench等基准,旨在评估多模态模型的性能和美学感知能力,以推动人工智能的发展。
本文介绍了多模态视频理解的最新进展,包括LongVLM和VideoLLM模型,这些模型通过分解长视频并利用大型语言模型(LLMs)实现了优越性能。此外,提出的多模态记忆模型(M3)和LongMem框架增强了视觉-文本依赖关系和历史上下文的利用,推动了视频理解的研究。
本文探讨了大型语言模型(LLM)在个性化对话生成、语言风格理解和对话摘要方面的应用。研究表明,Spoken-LLM框架在语言风格学习上优于传统模型,LLM在对话理解和生成中面临挑战。通过强化学习优化交互示例,LLM在教育和对话任务中表现出色,但在事实一致性和推理能力上仍需改进。
通过使用多模态编码器将开源大语言模型(LLM)与多模态输入指令结合起来,我们提出了 Tool-LMM 系统,使学习的 LLMs 能够意识到多模态输入指令并正确选择匹配功能的工具,实验证明我们的 LMM 能够为多模态指令推荐适当的工具。
该研究提出了一种新颖的LMM驱动的多模态人工智能,应用于放射治疗中的靶体积轮廓任务,并在乳腺癌放疗靶体积轮廓的背景下进行验证。该模型相比传统的仅视觉AI模型具有明显改进的性能,特别是在具有鲁棒泛化性能和数据效率的方面。这是第一个将临床文本信息整合到放射肿瘤学的靶体积划定中的LMM驱动多模态AI模型。
完成下面两步后,将自动完成登录并继续当前操作。