

可扩展多模态模型服务的编码器解耦
💡
原文英文,约1700词,阅读约需7分钟。
📝
内容提要
现代大型多模态模型(LMM)在服务时效率低下,因视觉编码器与文本生成阶段共享资源。通过将视觉编码器独立服务化,可以实现流水线执行,消除干扰,提高吞吐量并降低延迟,从而优化资源分配和提升多模态请求处理效率。
🎯
关键要点
- 现代大型多模态模型(LMM)在服务时效率低下,视觉编码器与文本生成阶段共享资源。
- 将视觉编码器独立服务化可以实现流水线执行,消除干扰,提高吞吐量并降低延迟。
- 当前的编码器、预填充和解码阶段在同一GPU上运行,导致效率低下。
- 编码器与文本生成的干扰使得请求处理变慢且不稳定。
- 资源分配不合理,导致无法根据不同阶段的需求进行优化。
- 将视觉编码器分离为独立服务可以实现流水线执行,消除排队延迟。
- 每个阶段可以根据需求独立扩展,避免资源浪费。
- 中央编码器服务支持跨请求缓存,提高效率。
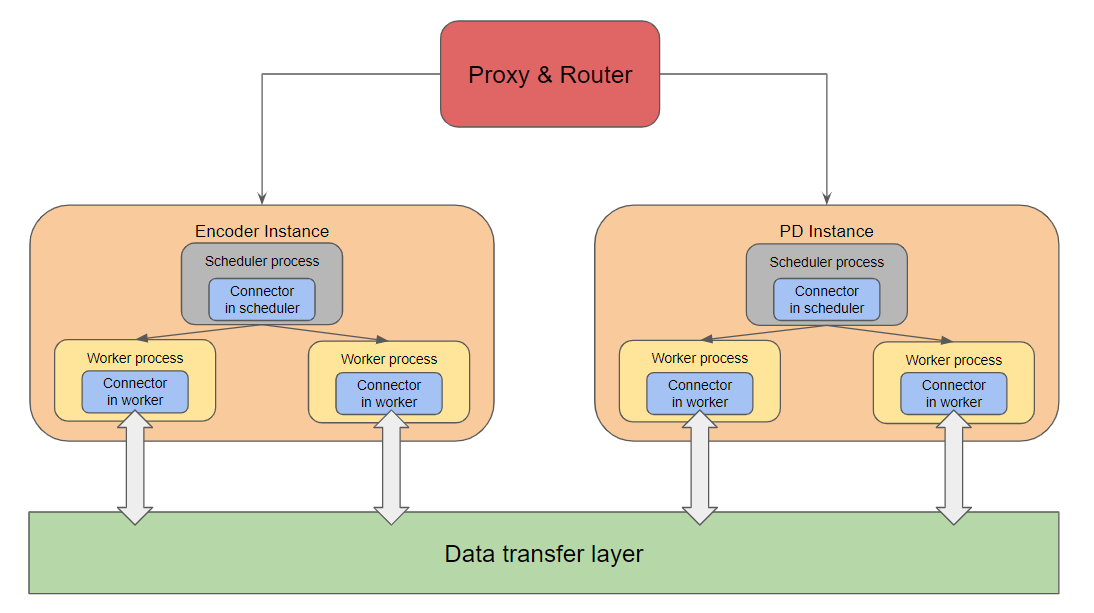
- 设计包括代理与路由、数据传输层和EC连接器,确保请求流畅。
- 性能测试显示,分离编码器后,吞吐量和延迟显著改善。
- 在不同硬件平台上,分离架构的优势得以验证,具有良好的可移植性。
- 通过分析LMM推理行为,开发出高性能的多模态服务架构,提升了系统稳定性和效率。
➡️
