
【多智能体强化学习】MAPPO 论文笔记
原文中文,约6500字,阅读约需16分钟。
📝
内容提要
本文介绍了多智能体强化学习算法MAPPO及五个调优建议,包括价值归一化、局部和全局特征输入、训练周期数、剪切比率和批量大小。MAPPO在多智能体环境中实现了与基于策略的方法相当的性能。
🎯
关键要点
-
MAPPO算法旨在通过简单修改证明PPO在多智能体环境中的优异性能。
-
MAPPO在多智能体环境中与基于策略的方法相媲美,且无需领域特定的算法修改。
-
MAPPO的实现与单智能体环境相似,通过学习策略和价值函数来实现。
-
MAPPO的五个调优建议包括:价值归一化、局部和全局特征输入、训练周期数、剪切比率和批量大小。
-
建议1:应用价值归一化来稳定价值学习。
-
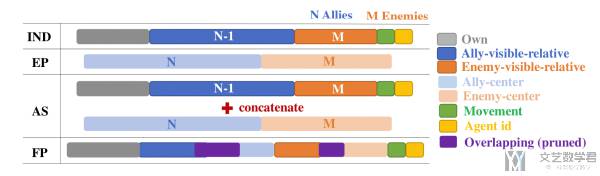
建议2:在价值函数的输入中包含本地特征和全局特征,确保不增加输入维度。
-
建议3:在困难环境中最多使用10个训练周期,在简单环境中使用15个训练周期,避免将数据分割成小批次。
-
建议4:保持剪切比率epsilon在0.2以下,以平衡训练稳定性和快速收敛。
-
建议5:使用较大的批次大小以优化MAPPO的任务性能。
❓
延伸问答
MAPPO算法的主要目标是什么?
MAPPO算法旨在通过简单修改证明PPO在多智能体环境中的优异性能。
MAPPO的五个调优建议是什么?
五个调优建议包括:价值归一化、局部和全局特征输入、训练周期数、剪切比率和批量大小。
如何应用价值归一化来稳定价值学习?
通过使用价值目标的平均值和标准差的动态估计来标准化价值函数的目标值。
在MAPPO中,训练周期数应该如何设置?
在困难环境中最多使用10个训练周期,在简单环境中使用15个训练周期,避免将数据分割成小批次。
剪切比率epsilon的最佳设置是什么?
为了获得最佳的PPO性能,应保持剪切比率epsilon在0.2以下。
MAPPO在多智能体环境中的表现如何?
MAPPO在多智能体环境中与基于策略的方法相媲美,且无需领域特定的算法修改。
🏷️
