
ChatGPT的模型训练
原文中文,约10800字,阅读约需26分钟。
📝
内容提要
本文介绍了ChatGPT模型的训练过程,包括无监督预训练、监督微调和指令微调。还介绍了Alpaca、Vicuna和ColossalChat的训练过程和代码。训练代码包括定义模型结构、损失函数和准备训练数据。奖励模型和强化学习模型的训练将在下一篇文章中介绍。
🎯
关键要点
-
本文介绍了ChatGPT模型的训练过程,包括无监督预训练、监督微调和指令微调。
-
开源模型Alpaca和Vicuna是基于Meta发布的LLaMA模型进行微调的。
-
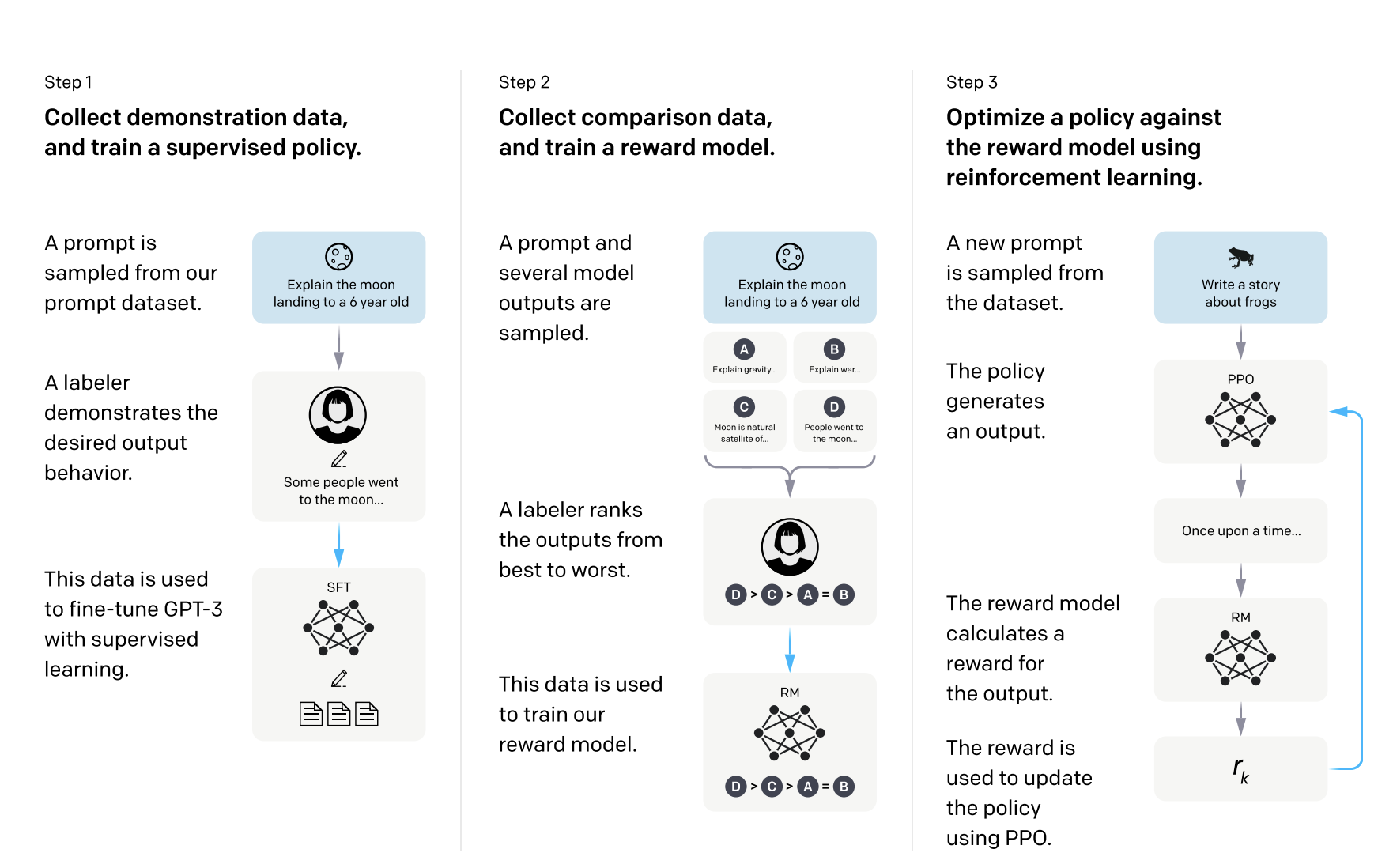
ChatGPT的训练过程分为三个阶段:无监督预训练、监督微调和指令微调。
-
无监督预训练使用大规模文本数据预测下一个词,监督微调则加入具体任务信息进行训练。
-
指令微调采用强化学习方案,分为三个步骤:数据抽取、回答排序和模型参数更新。
-
ColossalChat模型完成了完整的三个训练阶段,其他模型如Alpaca和Vicuna则只完成部分阶段。
-
训练代码主要包括定义模型结构、损失函数和准备训练数据。
-
Alpaca使用Self-Instruct机制生成多样性指令任务,Vicuna的数据质量更高。
-
ColossalAI实现了指令微调阶段的训练,包括监督微调和奖励模型的训练。
-
奖励模型通过比较生成的回答来评估质量,并用于训练强化学习模型。
-
强化学习模型的训练将在下一篇文章中介绍。
🏷️
