人们开始重新审视大型语言模型(LLMs),认为其进展并非完全错误。尽管DeepSeek R1等模型仍基于预测下一个词的解码器,缺乏明确的符号推理,但研究表明,少量示例足以让模型进行复杂推理。LLMs通过无监督预训练和强化学习,能够有效回答复杂问题。因此,认为LLMs无用的观点是不准确的。
本研究提出了DeepSeek-R1及其无监督预训练版本DeepSeek-R1-Zero,旨在提升大型语言模型的推理能力。通过多阶段训练,DeepSeek-R1在推理任务上表现优异,解决了可读性和语言混合等问题。
生成式AI模型如GPT的训练包括两个阶段:无监督预训练和有监督微调。前者通过大量文本数据学习语言模式,后者利用标记数据优化特定任务。
本研究比较了半监督学习中的预训练和自训练方法,发现预训练与微调组合效果最佳,自训练与半监督预训练结合未提供额外收益。其他研究探索了自监督正则化、贝叶斯深度学习、对比学习等方法在半监督学习中的应用,取得了显著提升。建议未来关注无监督预训练目标的半监督学习研究。
本研究提出了Counting Transformer(CounTR)和CLIP-Count等新技术,能够高精度计数任意语义类别的目标。通过无监督预训练和有监督微调,结合文本与图像生成模型,显著提升了零样本和少样本计数的性能,尤其在多个数据集上表现优异。
本文探讨了多种强化学习方法,包括FGI重标记策略、MapGo框架、自然语言标签结合机器人任务和离线动态适应学习。这些方法在复杂任务中提高了采样效率和任务成功率,展示了目标导向数据发现和无监督预训练在强化学习中的潜力。
本文介绍了一种新型GFlowNet学习算法Quantile Matching,旨在提高样本效率和匹配目标分布。通过优先回放和新策略参数化等方法,解决了激励波动性和结构学分配问题。此外,提出了无监督预训练的GFlowNets方法,增强了在下游任务中的适应性。研究表明,结合强化学习原理可提升生成流网络的效率,开辟了未来研究的新方向。
本研究提出了POVID、CG-VLM和VaLM等多种视觉与语言模型的改进方法,旨在解决幻觉问题并提升模型性能。通过无监督预训练和视觉增强,模型在多项视觉语言任务中表现优异,显著提高了准确性和推理能力。
本文介绍了GPT模型的底层原理和架构,以及在无监督预训练和有监督下游任务微调方面的应用。同时,还介绍了基于HuggingFace的预训练语言模型实践,包括数据集准备、训练词元分析器、预处理语料集合和模型训练等步骤。最后,给出了模型使用的示例。
该文介绍了一种使用Barlow Twins训练自监督编码器的技术,可以从未标记的数据中学习,减少注释样本的数量,并在语义场景分割任务中应用。实验结果表明,无监督预训练可以提高性能,特别是对于少数类别。
该文介绍了一种新型无监督整体预训练方法ProSeCo,利用基于Transformer的物体检测器生成的大量目标提案进行对比学习,从而允许使用较小的批量大小,并结合物体级特征学习图像中的局部信息。该方法在使用较少数据进行物体检测的无监督预训练中优于现有方法,在标准和新颖的基准测试中表现出色。
该文介绍了一种基于掩蔽自动编码器的无监督预训练技术,用于心电图心律失常分类任务。该方法在未标记数据的任务特定微调中表现出更好的性能,相较于全监督方法,在MITDB数据集上取得了94.39%的准确率。
研究人员通过Barlow Twins训练自监督编码器进行预训练,提出了一种从未标记的数据中学习的技术,以减少注释样本数量,并在语义场景分割任务中应用。实验结果表明,无监督预训练在有监督任务上进行微调后,能够显著提高性能,尤其是对于少数类别。
该论文提出了一种名为G-GNNs的新型模型,通过无监督预训练获取节点的全局结构和属性特征,并利用这些特征和原始网络属性提出了一种GNN的并行框架。该模型在平面图和属性图上进行了实验,并在三个标准评估图上表现出色,特别是在属性图学习方面,G-GNNs在Cora(84.31%)和Pubmed(80.95%)上建立了新的基准记录。
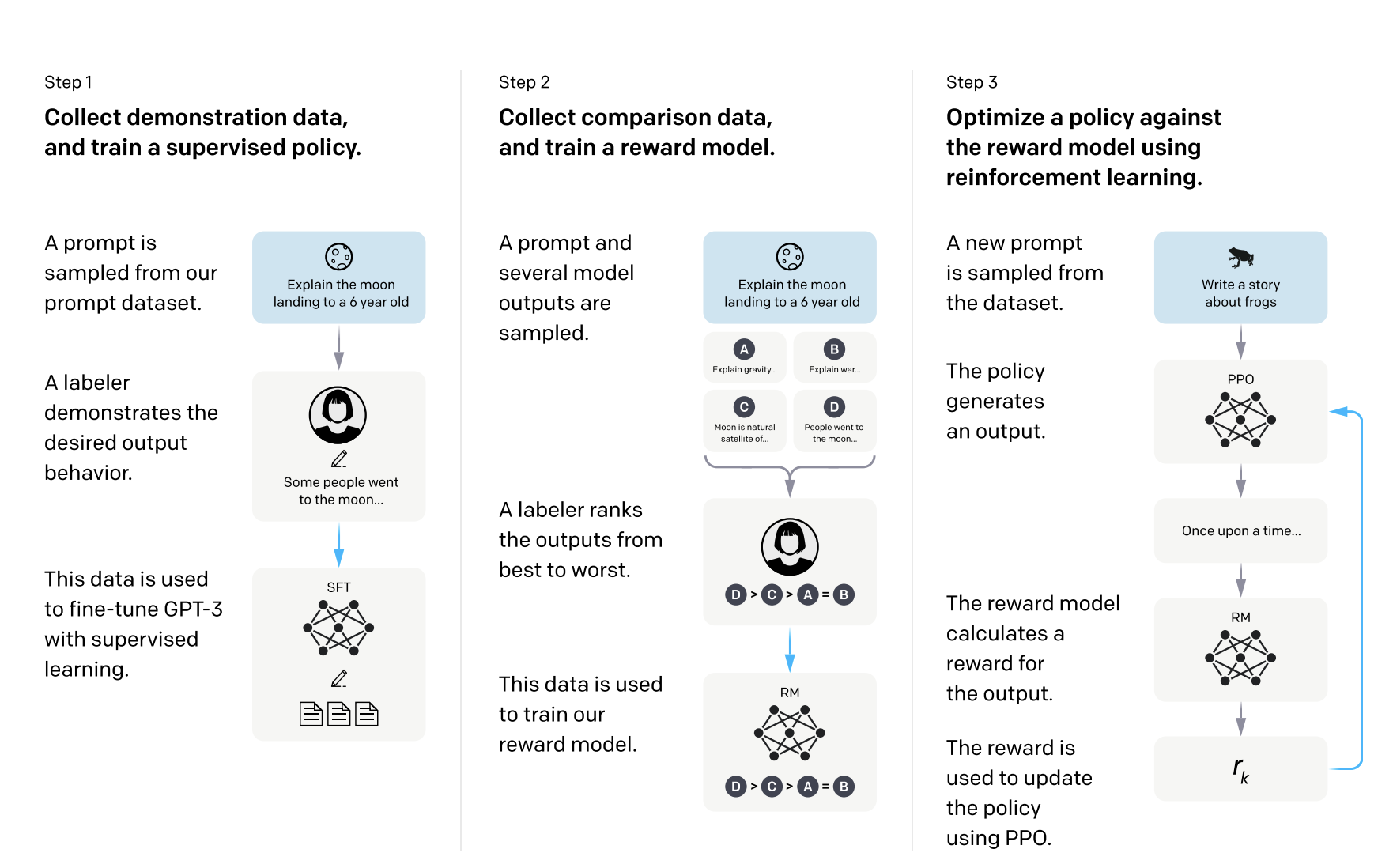
本文介绍了ChatGPT模型的训练过程,包括无监督预训练、监督微调和指令微调。还介绍了Alpaca、Vicuna和ColossalChat的训练过程和代码。训练代码包括定义模型结构、损失函数和准备训练数据。奖励模型和强化学习模型的训练将在下一篇文章中介绍。
我们在多语言任务上取得了先进成果,采用可扩展的无任务系统,结合变换器与无监督预训练,证明了监督学习与无监督预训练的有效结合,旨在激励更多研究。
完成下面两步后,将自动完成登录并继续当前操作。