

RLVR的力量:在Databricks上训练领先的SQL推理模型
💡
原文英文,约700词,阅读约需3分钟。
📝
内容提要
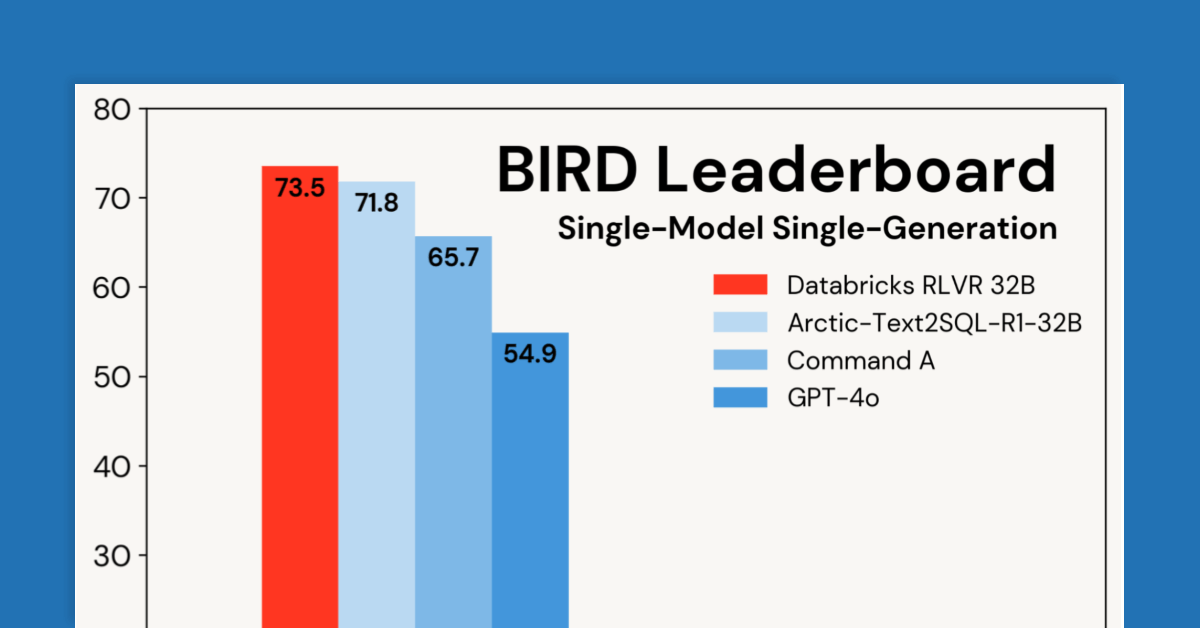
在Databricks,我们通过可验证奖励的强化学习(RLVR)开发推理模型,解决客户问题并提升产品性能。在BIRD基准测试中,我们取得73.5%的新高,证明了RLVR的有效性和易用性,帮助用户更好地与数据互动。
🎯
关键要点
- Databricks使用可验证奖励的强化学习(RLVR)开发推理模型,解决客户问题并提升产品性能。
- RLVR适用于生成代码、数据分析、整合组织知识、领域特定评估和信息提取等任务。
- 在BIRD基准测试中,Databricks的RLVR模型取得73.5%的新高,证明了其有效性和易用性。
- BIRD基准测试用于将自然语言查询转换为SQL代码,帮助非SQL专家与数据互动。
- Databricks的RLVR模型在BIRD基准测试中表现优异,超越了之前的最佳成绩71.8%。
- 使用标准的RLVR组件和BIRD训练集,Databricks实现了显著的性能提升。
- 通过精心选择模型和提示,Databricks在BIRD基准测试中取得了领先地位。
- Databricks客户在推理领域也报告了使用RLVR训练堆栈的良好结果,显示其广泛适用性。
➡️
