

💡
原文中文,约5000字,阅读约需12分钟。
📝
内容提要
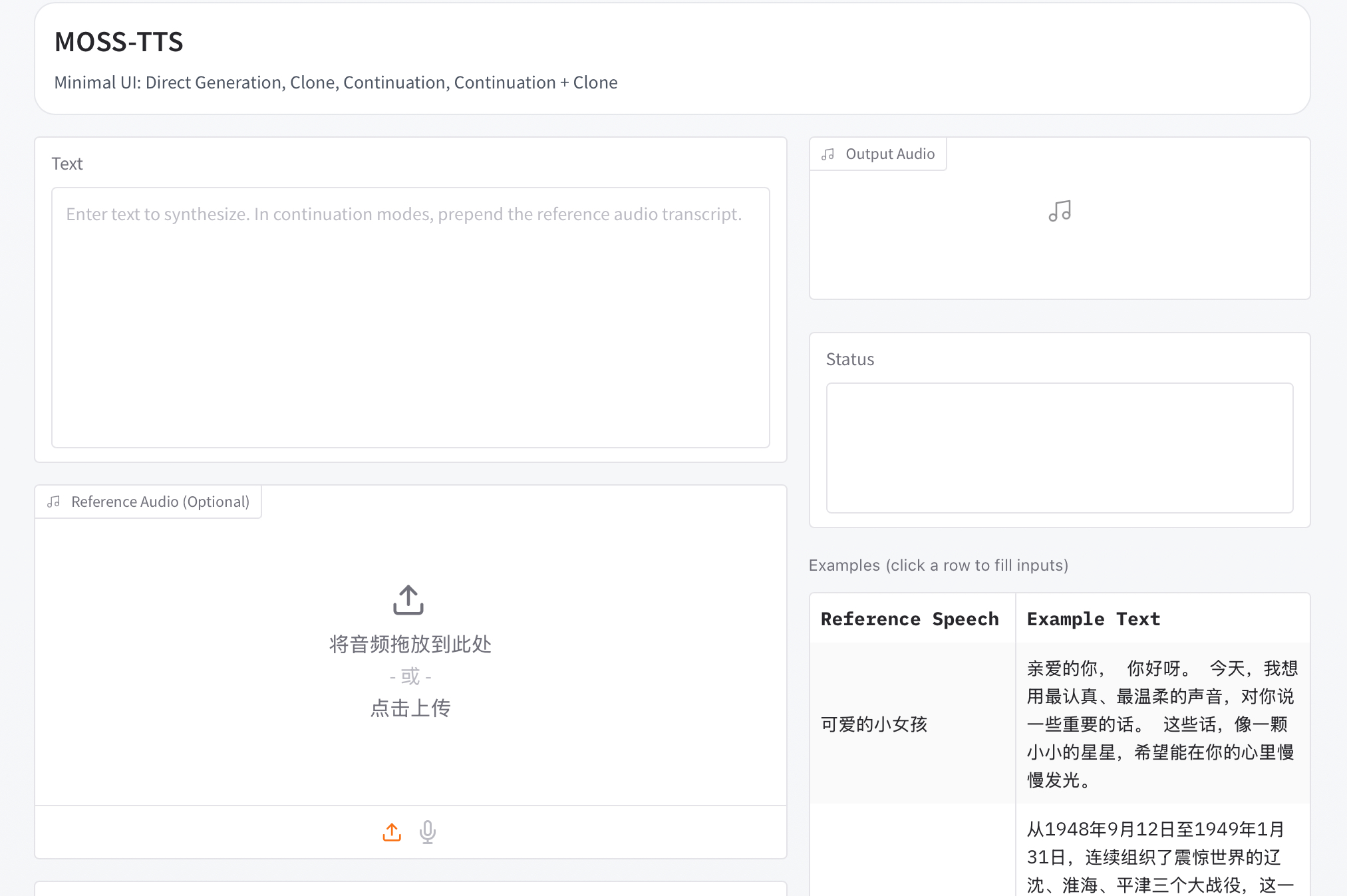
MOSS-TTS系列是MOSI.AI与OpenMOSS联合推出的多模型语音生成工具,克服了单一模型在复杂场景中的局限,支持高保真语音、对话和实时交互,适用于多种语言和风格切换。
🎯
关键要点
- MOSS-TTS系列是MOSI.AI与OpenMOSS联合推出的多模型语音生成工具。
- 该系列克服了单一模型在复杂场景中的局限,支持高保真语音、对话和实时交互。
- MOSS-TTS系列包含五个生产级模型,解耦了语音生成工作流。
- 核心技术基于1.6B参数的大规模音频分词器MOSS Audio-Tokenizer。
- 该系列模型支持20种语言,解决高保真零样本语音克隆等应用难题。
- HyperAI超神经官网已上线MOSS-TTS高保真多场景语音生成模型。
- 公共数据集包括无人机音频检测、模拟药物不良反应和癌症单细胞转录图谱数据集。
- 精选教程包括音乐生成Demo、语音识别系统和多功能语音识别模型。
- 社区文章解读涉及多模态整合局限、Qwen3-TTS语音克隆及MIT开发的酵母DNA学习模型。
- 热门百科词条包括视觉语言模型、超网络和人机回圈等。
➡️
