
Liquid AI 发布 LFM2-VL-3B,为边缘设备带来 3B 参数的视觉语言模型
内容提要
Liquid AI 发布了 LFM2-VL-3B,这是一个具有 30 亿参数的视觉语言模型,专用于图像文本到文本任务。该模型提高了准确率并保持了处理速度,支持高达 512×512 的图像输入,适合边缘设备使用,评估得分具有竞争力。
关键要点
-
Liquid AI 发布了 LFM2-VL-3B,这是一个具有 30 亿参数的视觉语言模型。
-
该模型专用于图像文本到文本任务,旨在提高准确率并保持处理速度。
-
LFM2-VL-3B 支持高达 512×512 的图像输入,适合边缘设备使用。
-
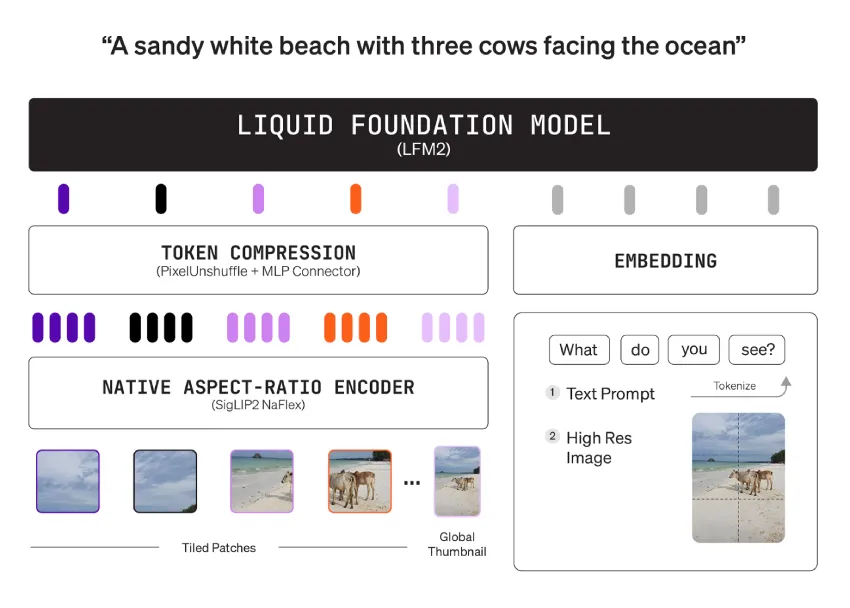
模型接受交错的图像和文本输入,并生成文本输出,提供类似 ChatML 的模板。
-
架构包括语言塔、形状感知视觉塔和投影器,允许用户限制视觉标记的预算。
-
模型的训练采用分阶段的方法,结合了大规模开放数据集和内部合成视觉数据。
-
在多个基准测试中,LFM2-VL-3B 的得分具有竞争力,如 MM-IFEval 得分 51.83。
-
该模型的多语言视觉理解能力扩展到多种语言,包括中文和英语。
-
边缘用户可以利用该架构的计算和内存优化,适合本地处理和严格数据边界的应用。
-
LFM2-VL-3B 提供开放权重和 GGUF 构建,降低了集成阻力。
延伸解读
边缘设备的优势
LFM2-VL-3B 模型专为边缘设备设计,支持高达 512×512 的图像输入,适合本地处理需求。这使得在数据隐私和实时处理方面具有显著优势,尤其适用于机器人和工业应用。
多语言支持的潜力
该模型的多语言视觉理解能力覆盖多种语言,包括中文和英语。这一特性使其在全球市场中具有更广泛的应用潜力,能够满足不同语言用户的需求,提升用户体验。
性能评估与竞争力
LFM2-VL-3B 在多个基准测试中表现出色,如 MM-IFEval 得分 51.83。这表明该模型在准确性和处理速度上具有竞争力,适合需要高效处理的多模态任务。
延伸问答
LFM2-VL-3B 模型的主要特点是什么?
LFM2-VL-3B 是一个具有 30 亿参数的视觉语言模型,专注于图像文本到文本任务,旨在提高准确率并保持处理速度,支持高达 512×512 的图像输入。
LFM2-VL-3B 如何处理图像和文本输入?
该模型接受交错的图像和文本输入,并生成文本输出,提供类似 ChatML 的模板。
LFM2-VL-3B 的训练方法是什么?
模型采用分阶段的方法进行训练,结合大规模开放数据集和内部合成视觉数据,进行联合中期训练和监督微调。
LFM2-VL-3B 在基准测试中的表现如何?
在多个基准测试中,LFM2-VL-3B 的得分具有竞争力,如 MM-IFEval 得分 51.83,RealWorldQA 得分 71.37。
为什么边缘用户应该使用 LFM2-VL-3B?
该模型架构优化了计算和内存,适合本地处理和严格数据边界的应用,特别适合机器人、移动和工业客户。
LFM2-VL-3B 支持哪些语言?
该模型的多语言视觉理解能力扩展到多种语言,包括中文和英语等。
