

💡
原文英文,约500词,阅读约需2分钟。
📝
内容提要
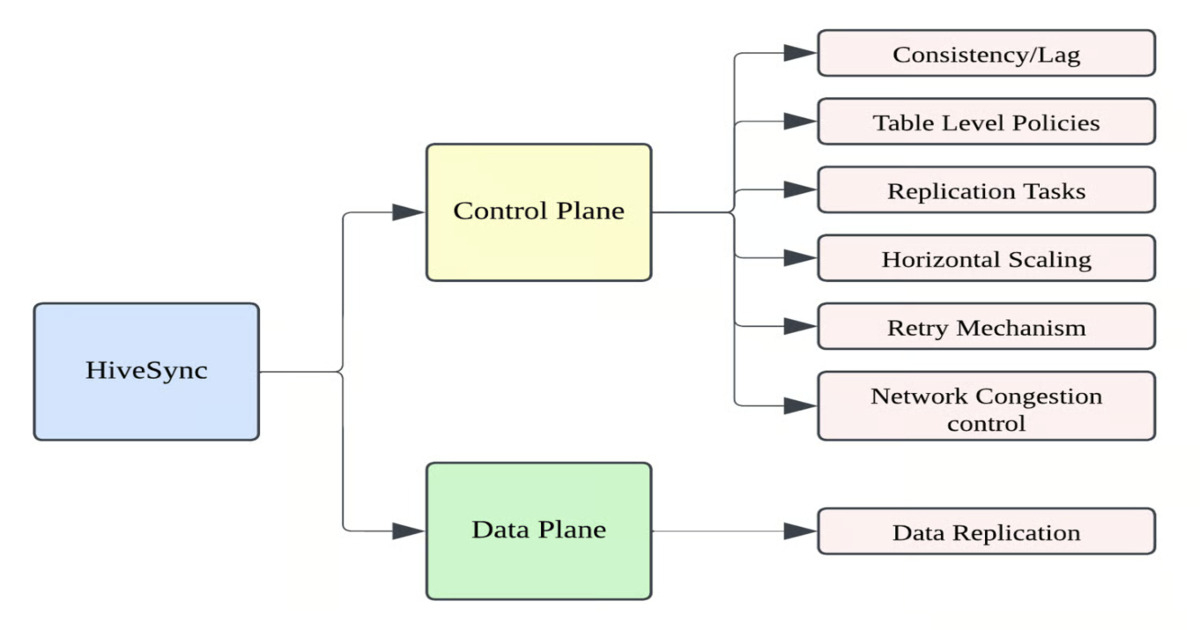
Uber开发了HiveSync,一个分片批量复制系统,确保Hive与HDFS数据在多个区域间同步,处理每日数百万个Hive事件。HiveSync提高了数据一致性,支持灾难恢复,消除闲置硬件成本。该系统包括控制平面和数据平面,实时捕捉DDL和DML变化,确保高可用性和数据准确性。
🎯
关键要点
- Uber开发了HiveSync,一个分片批量复制系统,确保Hive与HDFS数据在多个区域间同步,处理每日数百万个Hive事件。
- HiveSync提高了数据一致性,支持灾难恢复,消除闲置硬件成本。
- HiveSync最初基于开源的Airbnb ReAir项目,经过扩展,增加了分片、DAG基础的编排和控制平面与数据平面的分离。
- ETL作业在主数据中心执行,HiveSync处理跨区域复制,确保近实时一致性。
- HiveSync的控制平面负责作业编排和状态管理,数据平面执行HDFS和Hive文件操作。
- Hive Metastore事件监听器捕获DDL和DML变化,并记录到MySQL,触发复制工作流。
- HiveSync的两个主要组件是HiveSync复制服务和数据修复服务。
- 复制服务使用Hive Metastore事件监听器实时捕获表和分区变化,并异步记录。
- 数据修复服务持续检测异常,确保数据中心之间的一致性,目标是超过99.99%的准确性。
- HiveSync每天处理超过500万个Hive DDL和DML事件,复制约8PB的数据。
- Uber计划扩展HiveSync以支持云复制用例,进一步利用分片、编排和修复来维护PB级数据完整性。
➡️
