
IEEE TASLP | FPO: 细粒度偏好优化提升零样本TTS鲁棒性
内容提要
近年来,零样本文本转语音(TTS)系统取得进展,但仍存在局部错误。西工大与喜马拉雅合作提出细粒度偏好优化(FPO),有效修复问题片段,提升语音合成的鲁棒性和数据效率。实验结果显示,FPO在可懂度和自然度上显著优于传统方法。
关键要点
-
近年来,零样本文本转语音(TTS)系统取得进展,但仍存在局部错误。
-
西工大与喜马拉雅合作提出细粒度偏好优化(FPO),有效修复问题片段。
-
FPO在可懂度和自然度上显著优于传统方法。
-
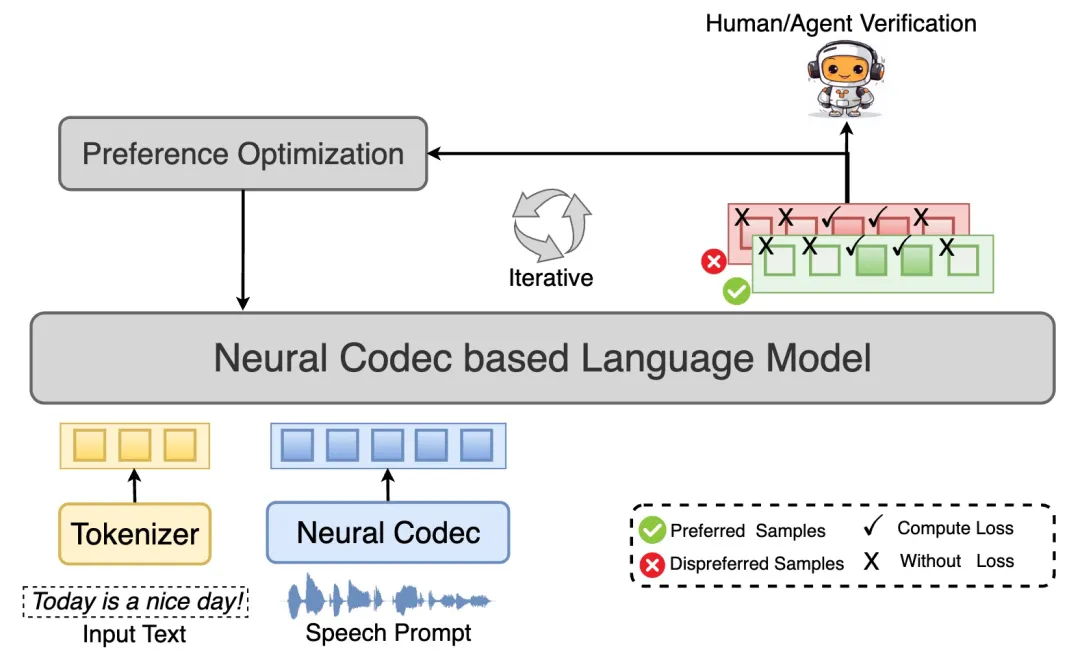
FPO将TTS的偏好学习从整句级别推进到token/片段级别。
-
FPO通过精准定位和修复问题片段,提升鲁棒性和数据效率。
-
传统的整句偏好优化方法存在效率低下和对良好片段的干扰问题。
-
FPO采用细粒度的错误分析与标注,确保标记准确。
-
FPO在多个主流零样本TTS系统上进行实验,显示出显著的性能提升。
-
FPO在小规模偏好数据实验中展现出明显的数据效率优势。
-
FPO的优势源于对优化目标的重新定义,避免了对良好生成片段的无效更新。
延伸解读
细粒度优化的优势
细粒度偏好优化(FPO)通过将偏好学习从整句级别转向token/片段级别,能够更精准地定位和修复语音合成中的问题。这种方法不仅提升了语音的可懂度和自然度,还显著提高了数据利用效率,尤其在小规模偏好数据的实验中表现出色。
传统方法的局限性
传统的整句偏好优化方法在处理局部错误时效率低下,可能对已经生成良好的片段产生干扰。FPO通过集中优化真正存在问题的片段,避免了这种无效更新,从而提升了整体语音合成的鲁棒性。
实验结果的意义
FPO在多个主流零样本TTS系统上的实验结果显示,其在可懂度和自然度上均优于传统方法。这表明细粒度优化不仅适用于性能较弱的模型,也能在高性能系统中有效发现并修复残余错误,具有广泛的应用潜力。
延伸问答
细粒度偏好优化(FPO)是什么?
细粒度偏好优化(FPO)是一种新的偏好优化方法,将文本转语音(TTS)的偏好学习从整句级别推进到token/片段级别,旨在精准定位和修复语音合成中的问题片段。
FPO如何提升零样本TTS的鲁棒性?
FPO通过精准定位和修复问题片段,避免对良好生成片段的无效更新,从而显著提升了零样本TTS的鲁棒性和数据效率。
FPO与传统的整句偏好优化方法有什么区别?
FPO与传统方法不同,它不再假设一句语音是整体好或坏,而是通过精细化标注和选择性优化,将学习信号集中在真正存在问题的片段上。
FPO在实验中表现如何?
实验结果显示,FPO在可懂度和自然度上显著优于传统方法,尤其在降低错误率和bad case比例方面表现突出。
FPO在数据效率上有什么优势?
FPO在小规模偏好数据实验中展现出明显的数据效率优势,使用更少的训练样本就能达到甚至超过其他方法的效果。
FPO的提出背景是什么?
FPO的提出背景是为了应对零样本TTS系统在真实使用场景中频繁出现的局部错误,提升生成语音的稳定性和自然度。
