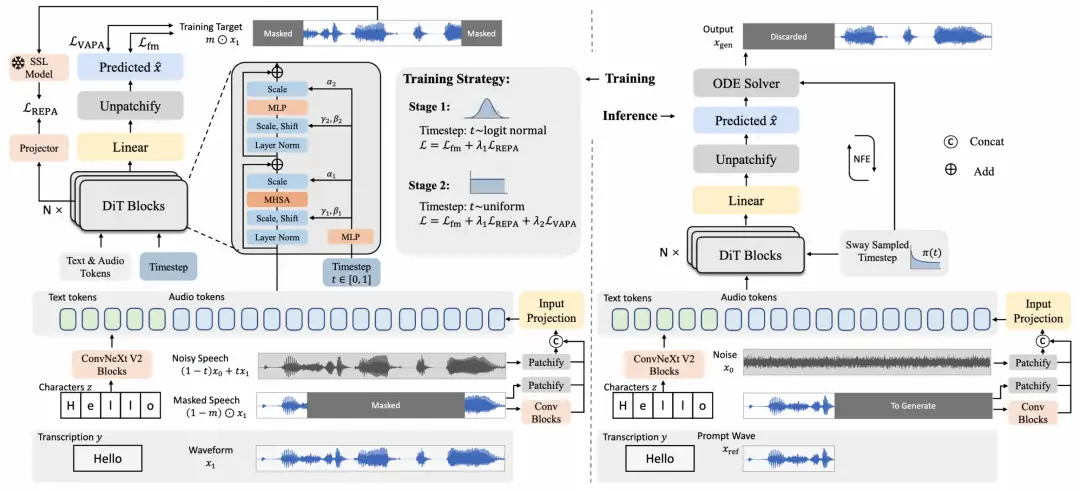
BareWave是一种全波形原生的零样本语音合成技术,能够直接从文本和参考音频生成目标说话人的波形,无需中间声学表示或独立声码器。实验结果表明,其在内容清晰度和说话人相似度上表现优异,开辟了新的语音合成方向。
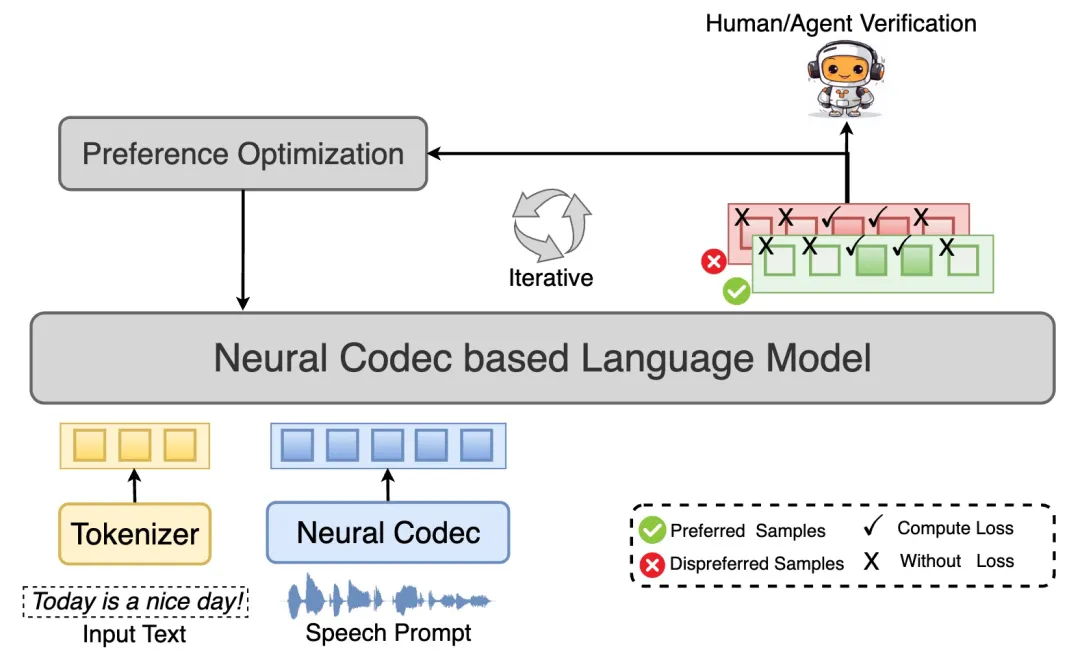
近年来,零样本文本转语音(TTS)系统取得进展,但仍存在局部错误。西工大与喜马拉雅合作提出细粒度偏好优化(FPO),有效修复问题片段,提升语音合成的鲁棒性和数据效率。实验结果显示,FPO在可懂度和自然度上显著优于传统方法。
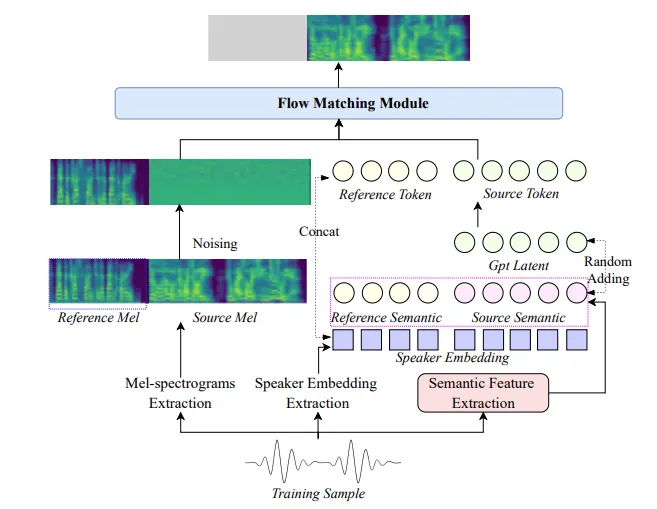
IndexTTS2是B站语音团队推出的新一代语音合成模型,优化了情感表达和时长控制。该模型通过“时间编码”机制解决了传统模型的时长控制问题,实现了音色与情感的解耦,并支持基于文本的情感调节。IndexTTS2在多项测试中表现优异,推动了零样本语音合成技术的实用化。
本研究提出了PDDLego+框架,旨在解决部分可观察环境中的规划问题,实现零样本迭代形式化和规划,展现出优越的性能和鲁棒性。
本研究提出了一种名为MultiActor-Audiobook的零样本有声书生成方法,能够自动生成具有一致性和表现力的语调与情感,无需额外训练,从而提升有声书的情感表现力。
本研究探讨了大型语言模型(LLMs)在社交媒体数据中识别和注释人权侵犯的能力。通过比较不同LLMs在零样本和少样本条件下的表现,揭示了它们在处理复杂文本时的错误模式及其在多语言背景下的适用性和局限性。
本研究提出MetaUAS,一种基于单一提示的元学习方法,旨在解决零样本和少样本视觉异常分割问题。MetaUAS通过将异常分割与变化分割统一,仅需一张正常图像即可精准分割未见的视觉异常,显著提升分割性能,无需依赖语言模型和特定数据集。
本研究提出了一种文本语义增强(TSA)方法,旨在解决文本属性图中的少样本和零样本节点分类问题。通过引入积极和消极语义匹配技术,TSA显著提高了分类准确率,实验结果表明其在多个数据集上超越了现有基线,准确度提升超过5%。
苏黎世大学等研究团队提出的vesselFM模型专为3D血管分割设计,具备零样本、单样本和少样本场景下的优越分割能力。该模型在大规模数据集上训练,能有效识别血管结构,推动心血管疾病的诊断与医学图像处理的发展。
本研究提出了一种后验与多样性协同的任务采样方法(PDTS),旨在解决顺序决策中的任务稳健适应问题,增强零样本和少样本的适应能力,加速学习过程。
本研究提出了一种基于扩散轨迹交集的无模型、零样本、免训练的文本到视频生成方法。该方法通过一致的帧内容生成和控制帧转换时机,显著提升了视频生成的时间一致性和视觉逼真度,实证分析显示用户满意度和量化指标均优于现有方法。
本研究提出了ConsDreamer框架,解决了零样本文本到3D生成中的视图偏差问题。通过改进得分蒸馏过程,提升了多视图渲染的一致性,超越了现有方法的视觉质量和一致性。
本研究探讨了多模态大型语言模型在深度伪造图像检测中的潜力,发现其在零样本情况下表现优于传统方法,显示了未来多模态推理整合的可能性。
本文提出了一种新的零样本无监督生物医学图像分割方法——注意力扩散零样本无监督系统(ADZUS)。该方法利用预训练的扩散模型,实现无需注释的医学图像分割,实验结果表明其在多种医学影像数据集上表现优异,具有广泛的应用潜力。
本研究提出FreeGrasp方法,利用视觉-语言模型理解人类指令与物体关系,有效解决机器人抓取问题。实验结果显示该方法在零样本设置下表现优异,具备应用潜力。
本研究提出了一种新的零样本人机协调方法,解决了未知环境中的泛化能力问题。通过改进效用函数和合作玩家采样策略,显著提升了自我代理与人类的协调性能,实验结果优于其他基线模型。
本研究提出SeqFusion框架,通过序列融合多种预训练模型,实现零样本时间序列预测。该方法根据目标时间序列特征选择最适合的模型,实验结果表明其预测准确性与先进方法相当。
本研究提出了一种零样本概念瓶颈模型(Z-CBMs),旨在解决传统概念瓶颈模型对大量数据和资源的依赖问题。Z-CBMs无需训练神经网络即可进行概念和标签预测,利用大型概念库进行检索和回归。实验结果表明,该模型具有可解释性和干预性,展现出重要的应用潜力。
本研究提出了一种基于大型语言模型的零样本决策树构建算法,解决了传统方法对标记数据的依赖。该算法利用预训练知识进行属性离散化和概率计算,能够在数据稀缺的情况下构建透明且可解释的模型。
本研究提出GLiREL模型,旨在提高零样本关系分类的效率和准确性。该模型通过一次前向传播预测多个实体关系标签,并在FewRel和WikiZSL基准测试中表现优异。
完成下面两步后,将自动完成登录并继续当前操作。