KVectors向量数据库现已支持IVF_RABITQ索引。测试显示,构建999999个向量的索引耗时7分25秒,尽管检索性能有所下降,但仍适合大规模数据集。该数据库支持多种主流向量索引,软著申请正在审核中。
本文提出了一种自适应空间标记化(AST)方法,旨在高效模拟可变形物体之间的交互。该方法通过将模拟空间划分为网格单元,并将非结构化网格映射到结构化网格上,从而提高计算效率。实验结果表明,该方法在处理超过10万个节点的大规模网格时,显著优于现有技术,并提供了一个新的大规模数据集以支持未来研究。
本文介绍了如何通过BigQuery简化数据科学工作,提供八种实用方法,如在电子表格中进行机器学习、使用BigQuery Sandbox进行无成本实验、在Colab笔记本中利用AI助手,以及处理大规模数据集等。这些工具旨在帮助数据科学家专注于分析,而非工具本身。
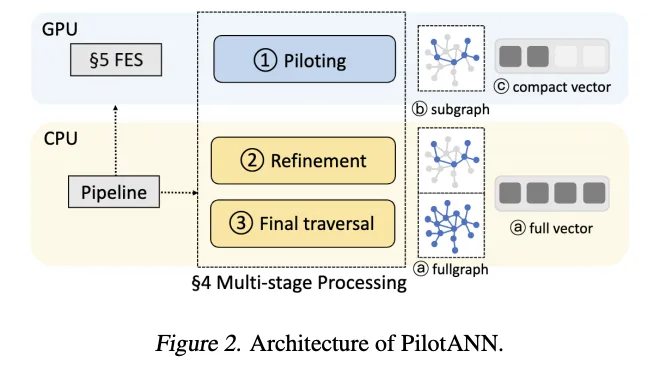
近似最近邻搜索(ANNS)是一种用于高维向量检索的技术,广泛应用于搜索引擎和推荐系统。香港中文大学等提出的PilotANN通过混合CPU-GPU系统优化了向量搜索,显著提升了吞吐量和成本效益,适合大规模数据集。
本文介绍了一种新颖的机器遗忘方法LoTUS,旨在消除训练样本对预训练模型的影响,避免重新训练。LoTUS通过平滑模型的预测概率,减轻数据记忆导致的过度自信。实验表明,LoTUS在效率和效果上优于现有方法,尤其在大规模数据集上表现出良好潜力。
本研究提出了一种新方法:粒状球支持向量回归(GBSVR),旨在解决支持向量回归(SVR)在处理大规模数据集时的高计算成本和对异常值敏感的问题。GBSVR通过将数据点聚集为少量球体来简化计算,并在多个基准数据集上表现优于现有方法。
DeepSeek 开源周发布的 3FS 是为 AI 高性能计算设计的分布式并行文件系统,优化大规模数据集处理,支持高 IOPS 和吞吐量,提升推理任务性能。
本文提出了一种改进的耦合Adam优化器,以解决大型语言模型在学习词表示时的各向异性问题。实验结果表明,耦合Adam显著提高了嵌入质量,并优化了大规模数据集的任务性能。
该研究提出Kozax框架,旨在解决遗传编程中适应性评估的高计算需求问题,支持大规模数据集和自定义运算符,展示了在科学计算中的优化潜力。
HNSW算法在小型数据集上表现良好,但在大规模向量相似性搜索中存在内存依赖和性能下降的问题。相比之下,IVF算法通过减少距离计算和优化量化技术,提供了更高效的解决方案,特别适合大规模数据集,因其简洁性和可扩展性而更具实用性。
本研究提出了一种基于因果图模型的视觉-语言解码器,旨在提升对人类语言组合特性的理解。实验结果显示,该方法在多个基准测试中显著优于现有技术,并在大规模数据集上表现更佳。
本研究提出了一种新方法,通过谱数据压缩加速UMAP,解决了其在大规模数据集上的效率问题。该方法在减少数据集大小的同时保持流形结构,实验结果表明嵌入质量未受影响。
本文研究了数据摘要中的公平聚类问题,特别是公平 k-供应商问题。提出了两种 3-近似算法,能够在大规模数据集上有效选择中心点,最小化目标函数,并在公平约束下具有实用性。
本文研究了影响函数在大规模数据集中的应用,发现其预测效果与实际效果显著相关。探讨了影响函数在NLP模型和神经网络中的有效性,提出了新的评分方法和算法,解决了微调过程中的高成本问题,并展示了在减少训练数据的情况下仍能保持性能的潜力。
本文提出了一种名为Subject-Diffusion的开放域个性化图像生成模型,能够通过参考图像实现个性化生成。研究构建了一个包含7600万图像的大规模数据集,并设计了统一框架以提高生成准确性。该模型在单一和多主体生成方面优于现有技术,采用注意力控制机制增强生成效果。
OpenUSD是一个强大的框架,用于处理和分析复杂数据模型。它具有统一的数据模型、可扩展性和通用性,适用于数据科学工作流和流水线。通过模式插件和Hydra 2.0中的运行时内核的可扩展性,OpenUSD能够高效处理和分析大规模数据集,实现更快速和可扩展的计算。数据科学家应该探索和利用OpenUSD等工具,发掘数据驱动努力的潜力。
本研究提出了一种基于动态规划和搜索的学习算法,用于优化决策树,支持深度和节点数量限制。实验表明,该算法能够快速处理大规模数据集,提高决策树的实用性。同时,研究探讨了基于强化学习的组合优化方法,解决了不平衡数据和连续变量的优化问题,显著提升了构建速度和性能。
本文提出了一种新型局部自适应带宽径向基函数核,增强了核的灵活性,并建立了非对称核岭回归框架。实验结果表明,该算法在大规模数据集上的回归准确度优于现有方法,甚至超过了残差神经网络。
COVESA是一个专注于连接车辆系统的行业联盟,与MongoDB合作并标准化以加快开发。MongoDB通过其处理大规模数据集的专业知识为COVESA做出贡献。他们提供Atlas Device SDK和支持车辆信号规范(VSS)。MongoDB的贡献包括数据管理洞察和支持标准化工作。MongoDB最近与AWS合作,在CES 2024展示了其连接车辆解决方案。他们旨在提升最终用户体验并赋予汽车行业的原始设备制造商更多权力。
本文研究了标签比例学习(LLP)模型在监督学习中的应用,提出新的学习框架和算法以提升分类器性能,适用于政治、营销和医疗等领域。同时,提出改进技术以解决标签噪声问题,并评估多种先进LLP技术在大规模数据集上的表现。
完成下面两步后,将自动完成登录并继续当前操作。